이미지 분야 Anomaly Detection 딥러닝 모델 비교
본 포스트에서는 이미지 분야에서 Anomaly Detection과 Anomaly Localization을 위해 고안된 딥러닝 모델들을 비교해 보려고 합니다. Anomaly Detection이 Anomaly Localization을 포괄하는 용어로써 자주 사용되고 있는 것 같긴 하지만 좀 더 구체적으로 용어를 정의해 본다면, Anomaly Detection은 이미지 전체에 anomaly score를 부여하여 이미지 자체의 정상, 비정상을 분류합니다. Anomaly Localization은 이미지 내 각각의 픽셀에 anomaly score를 부여하여 이미지의 어느 부분에서 비정상성이 나타나는지까지 보여줍니다. Anomaly Detection 보다 좀 더 까다롭지만 더 정확하고, 해석 가능한 결과를 도출한다는 장점이 있습니다.
모델들을 비교하기에 앞서, 먼저 Anomaly Detection 문제 해결이 어려운 이유를 살펴보면 다음과 같습니다.
- 비정상 이미지가 극히 적은 데이터 불균형 문제
- 비정상 패턴이 모호하고, 테스트 시에 새로운 패턴이 나타날 가능성이 있음
- 특히 산업 이미지 데이터는 비정상 패턴이 다양해서 까다로움
위와 같은 문제 때문에 많은 Anomaly Detection 모델들이 정상 데이터만을 학습에 사용하는 one class classification 방식을 사용하는데요. 오늘 비교 대상 모델들도 모두 one class classification 방식을 사용합니다. 또한 ImageNet 데이터 기반의 pre-trained CNN 모델을 사용해 이미지의 feature를 추출하고, 이 때 여러 layer로부터 구한 feature를 종합적으로 고려하는 방식을 사용했다는 공통점이 있습니다. CNN 모델의 마지막 layer로부터 구한 feature만 사용한다면 아래와 같은 문제가 발생합니다.
- 입력 이미지는 convolution layer를 거치면서 점차 위치 정보를 잃게 됩니다. 마지막 layer에서는 위치 정보가 거의 존재하지 않는 추상적인 feature를 생성합니다. 이 경우 localization 성능이 크게 떨어집니다.
- 마지막 layer에서는 ImageNet 데이터 기반의 classification task에 편향된 feature를 생성합니다.
따라서 최근 몇 년 사이에 발표된 모델들 모두 공통적으로 pretrained model의 여러 layer에서 featrure를 뽑아 concatenate 하는 방식을 사용하는데요. feature의 구체성과 추상성을 함께 취해 localization과 detection 성능을 모두 향상시키기 위함입니다.
1. 분석 단위의 변화: pixel에서 patch로
SPADE는 pixel 단위로 유사도를 비교하는데, PaDiM부터는 patch로 쪼개어 비교하기 시작합니다.
2. PaDiM은 이미지 정렬이 중요한 모델
PaDiM은 영역의 분포를 학습하기 때문에 이미지 정렬이 중요한 모델입니다. 반면에, SPADE는 모든 pixel feature들 사이의 거리를 산출하기 때문에 이미지 정렬에 영향을 받지 않습니다. 이러한 이유로 SPADE보다 Texture에는 높은 성능을 보이는데, Object에는 낮은 성능을 보입니다.
또한 PaDiM은 다른 모델과 달리, train, test 이미지 shape 동일해야 한다는 치명적 문제점도 가지고 있습니다.
3. 추가 학습이 필요한 모델
CFA, ReConPatch는 다른 모델들과 달리 추가 학습이 필요한 모델입니다. ImageNet 데이터셋과는 다른 산업용 이미지의 특성을 학습할 수 있습니다.
4. memory bank의 크기 비교
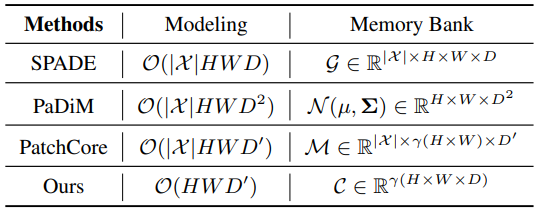
CFA는 학습 데이터셋의 크기와 관계없이, 사용자가 지정한 $K$개 만큼의 feature vector를 뽑아 memory bank를 구성합니다. 다른 모델들도 sampling 방식을 사용해 memory bank의 크기를 제한할 수 있는데요. memory bank가 너무 크면 inference time이 증가하고, memory bank가 너무 작으면 대표성이 떨어져서 성능을 보장할 수 없습니다. 따라서 데이터셋을 잘 대표하는 memory bank를 구성하는 것이 중요합니다.
5. PatchCore, ReConPatch 비교
공통점
- locally aware patch-feature를 생성합니다.
- memory bank를 효과적으로 구성하기 위한 greedy coreset sampling 사용합니다.
- vector similarity 검색 모델로 Faiss를 사용합니다.
차이점
- PatcCore와 달리, ReConPatch는 추가 학습이 필요합니다.
- ReConPatch는 anomlay detection 성능 개선에 중점을 둔 모델로, anomaly segmentation 성능이 중요하다면 PNI, CFA 사용하는 것이 적절합니다.
- ReConPatch가 PatchCore보다 대체로 개선된 성능을 보입니다.
6. 테스트 시 anomaly score 산출 방식 비교
SPADE
학습 데이터 중 테스트 이미지와 가장 가까운 $K$개의 이미지(KNN)를 선별. 테스트 이미지와 해당 $K$개 이미지들의 유클리디안 거리 평균을 전체 이미지의 anomaly score로 사용
\[d(y)=\frac{1}{K} \sum_{f \in N_{K}(f_y)}||f-f_y||^2\]해당 이미지들과 테스트 이미지 내 pixel feature의 유클리디안 거리를 계산
계산된 거리들 중 가장 가까운 $\kappa$개 pixel feature들의 평균 값을 계산하여 개별 pixel의 anomaly score로 사용
\[d(y,p)=\frac{1}{\kappa}\sum_{f \in N_{\kappa}(F(y,p))}||f-F(y,p)||^2\]
PaDiM
- 학습 데이터를 통해 multivariate gaussian(MVG) 분포를 구함
- 이 분포와 테스트 이미지 내 patch feature의 마할라노비스 거리를 구함
- patch 별 마할라노비스 거리를 담은 matrix를 anomaly map으로 사용하고, 이 matrix의 값 중 최댓값을 전체 이미지의 anomaly score로 사용
PatchCore, ReConPatch
- coreset subsampling 기법을 사용해 memory bank 구성
- memory bank 내 patch feature들과 테스트 이미지 내 patch feature들 사이의 유클리디안 거리를 구함
CFA
최초에 K-means clustering을 통해 $K$개의 patch feature를 가진 memory bank 구성
학습 데이터셋에서 구한 patch feature들이 memory bank의 feature들과 가까워지도록 feature 업데이트 (별도의 학습 과정이 필요함)
테스트 이미지 내 patch feature $\phi(p_t)$와 가장 가까운 $k$개의 memory bank featrue $c_t$ 사이의 유클리디안 거리를 구하고, 그 최솟값을 계산
\[\mathcal{S}_t=\min_{k}\mathcal{D}(\phi(p_t), c_t^k)\]단순히 거리 최솟값 $\mathcal{S}_t$를 anomaly score로 쓰는 것이 아니라, softmin 값을 구해서 이를 해당 patch의 anomaly score로 사용. 다른 $k-1$개의 memory bank featrue $c_t$와 비교해 얼마나 가까운지 상대적인 거리를 측정하려는 것
Code | 산출 방식 | 크기 | CNN | ||
|---|---|---|---|---|---|
| SPADE | image level | ||||
| Mahalanobis AD | link | Mahalanobis distance | ResNet | ||
| PaDiM | Mahalanobis distance | wide ResNet50 EfficientNet-B5 | |||
| PatchCore | link | ||||
| CFA | link | wide ResNet50 EfficientNet-B5 | |||
| ReConPatch |