[Paper Review] Alpaca: A Strong, Replicable Instruction-Following Model
오늘 소개할 Alpaca는 Stanford에서 LLaMA 7B를 기반으로 만든 파생 모델입니다. LLaMA 자체는 단순 언어 모델인데, LLaMA에 instruction tuning을 거쳐 나온 모델이 바로 Alpaca입니다. instruction tuning은 모델이 사용자의 지시문을 이해하고, 그 지시에 맞춰 작업을 수행하도록 학습시키는 과정을 의미하는데요. instruction tuning을 위해서는 아래와 같이 지시문과 출력으로 이루어진 데이터가 필요합니다.
Instruction: Translate the sentence “I love machine learning” to French.
Output: J’aime l’apprentissage automatique.
Alpaca는 이러한 instruction data를 GPT-3.5 API를 사용해 아주 저렴하게 만드는 방법을 보여주었다는 점에서 큰 의미를 갖는 모델입니다. Alpaca의 모델 구조와 instruction data를 만든 과정을 좀 더 자세히 살펴보겠습니다.
1. 모델 구조
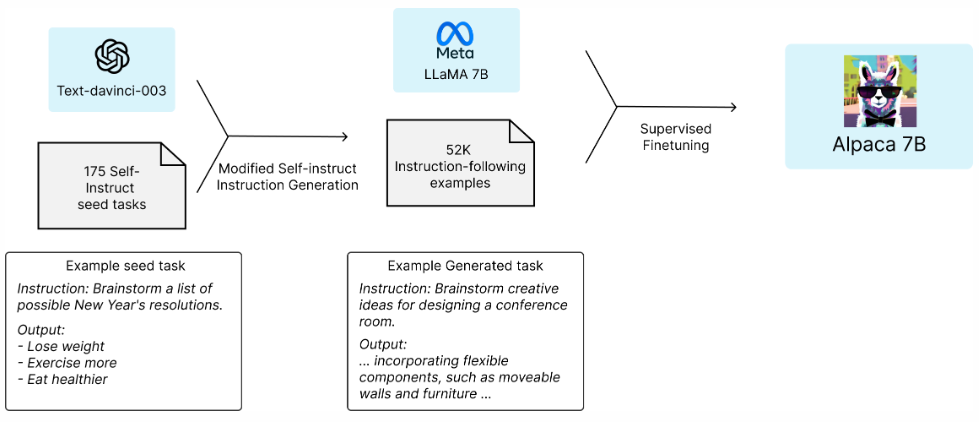
Self-Instruct Instruction Generation
먼저, 사람이 직접 작성한 seed instruction set 175개를 수집했습니다. 그리고 이를 GPT-3.5에 프롬프트로 입력하여 지시문-출력 데이터를 생성하도록 했습니다. 이처럼 LLM에게 프롬프트를 만들어 달라고 지시하는 상위 레벨의 프롬프트를 메타-프롬프트라고 부릅니다.
결과적으로 Alpaca 연구진은 OpenAI API 호출 비용 약 500달러로 52,000개의 데이터셋을 생성해 냈습니다. 사람이 같은 양의 데이터를 만들 때 드는 비용보다 훨씬 저렴한 비용으로 학습용 데이터셋을 생성한 것입니다. Alpaca github repository를 참고해 구체적인 Self-Instruction 과정을 정리해보면 아래와 같습니다.
| 단계 | 상세 과정 |
|---|---|
| 1. seed instruction set 준비 | 사람이 직접 작성한 seed instruction set 175개를 수집 |
| 2. 메타-프롬프트 | “중복되지 않는 task(instruction, input, output)를 20개씩 만들어 달라”는 규칙을 명시하고, 위 175개의 예시 중 3개를 in-context로 넣음 (prompt.txt) |
| 3. 대량 생성 | OpenAI GPT-3.5(T=0.7, top-p=0.95 기본값) 한 번 호출당 20개의 task 생성 |
| 4. 후처리 간소화 | 길이/중복만 간단히 필터링해서 최종 52K 샘플 확보 (alpaca_data.json) |
Supervised Finetuning
생성된 52,000개의 데이터셋을 LLaMA 7B 모델에 학습시켜 instruction-tuning을 진행했습니다. 그 결과로 만들어진 모델이 Alpaca 7B입니다.
2. 모델 성능 및 한계점
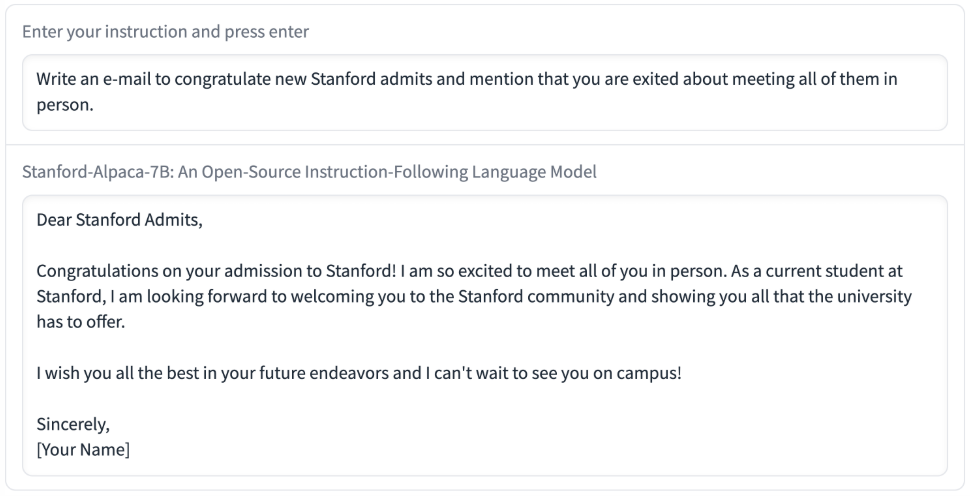
위 예시는 Alpaca 7B 모델이 실제로 생성한 답변 중 일부입니다. 사람이 직접 Alpaca 모델의 성능을 평가했을 때, GPT-3.5와 비슷한 품질의 답변을 생성했습니다.
하지만 Alpaca는 Hallucination, 유해 발화, 편향 등 LLM이 안고 있는 근본적인 문제들을 여전히 갖고 있습니다. 기본적으로 LLaMA 7B 모델을 기반으로 만들어진 모델이고, GPT-3.5가 생성한 데이터를 정답으로 간주하고 학습했기 때문입니다. 또한 Supervised Fine-tuning(SFT) 이후에 RLHF과 안전 훈련 등은 수행하지 않았기 때문에 답변의 정확성과 안전성 측면에서 성능이 개선되지 못했습니다.