[Paper Review] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT는 대용량 corpus로 pre-training한 모델의 파라미터를 target task 수행을 위한 labeled data 학습 과정에서 fine-tuning하는 transfer-learning 모델입니다. Transformer의 Encoder만으로 구성되어 있다는 특징이 있습니다.
선행 연구와의 비교
BERT의 대표적인 선행연구로는 ELMo와 OpenAI GPT가 있습니다. 이 모델들은 pre-trained word embedding vector를 target task에 적용할 때 각각 feature-based 방식과 fine-tuning 방식을 따른다는 차이점이 있습니다. ELMo는 target task에 특화된 구조를 사용하고, pre-trained word embedding vector를 업데이트 하지 않고 추가적인 feature로써 사용합니다. 반면, OpenAI GPT는 어떤 target task를 수행하든 비슷한 구조를 사용하고, pre-trained word embedding vector를 업데이트합니다.
BERT는 OpenAI GPT와 같이 fine-tuning 방식을 사용하는데요. BERT가 ELMo, OpenAI GPT와 갖는 차별성은 pre-training 시 Masked Language Model을 학습하여 양방향 문맥을 종합적으로 고려한 word embedding vector를 얻을 수 있다는 점입니다.
Only BERT representations are jointly conditioned on both left and right context in all layers
BERT 모델 구조
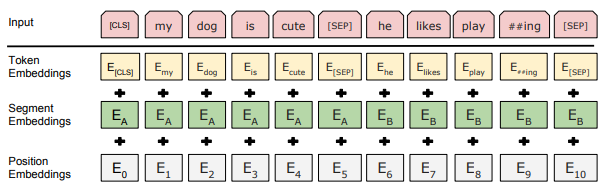
본 논문에서 sequence는 일련의 input 토큰을 의미합니다. 하나의 sequence는 하나의 문장일 수도 있고, 짝 지어진 두 개의 문장일 수도 있습니다. [CLS]는 sequence 시작을 알리는 토큰입니다. 이 토큰에 해당하는 final hidden state는 입력된 sequence를 표현하는 임베딩 벡터로써 분류 task에 사용됩니다. [SEP]는 짝 지어진 두 개의 문장을 구분하는 토큰입니다. token embeddings, segment embeddings과 position embeddings의 합으로 이루어진 input representation가 Transformer encoder에 입력됩니다.
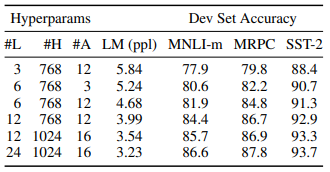 모델 사이즈별 실험 결과
모델 사이즈별 실험 결과
본 논문에서는 사이즈에 따라 두 가지 타입의 모델 $BERT_{BASE}$와 $BERT_{LARGE}$를 제안했는데요. 저자들의 실험에 따르면, 모든 NLP task에서 모델 사이즈가 커질수록 성능이 향상되었다고 합니다.
| BASE | LARGE | |
|---|---|---|
| 레이어의 개수 | 12 | 24 |
| final hidden vector의 크기 | 768 | 1024 |
| attention head의 개수 | 12 | 16 |
| 총 파라미터 개수 | 110M | 340M |
Pre-training BERT
Task #1: Masked Language Model (MLM)
언어 모델은 기본적으로 한 방향으로만(left-to-right or right-to-left) 학습할 수 있습니다. 양방향 연산을 수행하면 미래나 과거의 스스로를 간접적으로 참고(see itself)할 위험성이 있기 때문입니다. 이 때문에 BERT의 선행 연구들은 단방향 언어 모델을 사용했습니다. ELMo가 문장의 순방향과 역방향 문맥을 모두 고려하기는 하지만, 독립적으로 학습된 LSTM status를 단순히 이어 붙이는 것에 불과하다는 한계점이 있습니다. 이러한 접근 방법으로는 word embedding vector를 사전 학습하는 방식의 강점을 충분히 살릴 수 없습니다.
BERT는 양방향 연산으로 인한 위험성을 해소하면서 좌우 문맥을 고려한 word embedding vector를 학습하기 위해 Masked Language Model(MLM)을 사용합니다. MLM은 input 토큰들 중 일부를 랜덤하게 마스킹 처리하고, 문맥상 가려진 토큰이 무엇인지 예측하는 모델입니다. left-to-right 언어 모델과 달리, 좌우 문맥을 융합할 수 있게 하므로 deep bidirectional Transformer를 학습할 수 있습니다. 마스킹 처리를 할 때는 [MASK] 토큰을 사용하는데, 이 토큰은 pre-training 단계에서만 등장하고, fine-tuning 단계에서는 등장하지 않습니다.
Task #2: Next Sentence Prediction (NSP)
문장 관계를 이해하는 모델을 학습하기 위해서 어떤 두 문장이 이어지는 문장인지 아닌지 맞추는 next sentence prediction task를 수행합니다. pre-training example에서 sentence A와 B를 고를 때, 절반은 실제로 이어지는 두 문장을 고르고 나머지 절반은 랜덤하게 고릅니다.
Pre-training Task의 효과
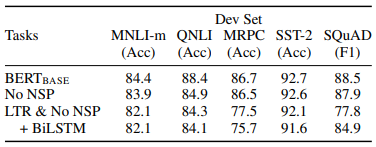 pre-training task의 효과 검증 결과
pre-training task의 효과 검증 결과
저자들의 실험에 따르면, MLM과 NSP 모두 BERT에서 큰 역할을 담당하고 있습니다. 위 실험에서 SST-2 데이터셋은 다른 데이터셋에 비해 큰 영향을 받지 않는데요. 문장 길이가 짧고, 문장의 긍정/부정을 분류하는 비교적 단순한 task이기 때문인 것으로 추측됩니다.
1) No NSP
MLM은 사용하고 NSP는 사용하지 않았을 때 MNLI, QNLI, SQuAD 데이터셋에서 성능 하락을 보였는데요. NSP가 짝 지어진 두 문장의 관계를 이해하기 위해 고안된 모델이기 때문에 자연어 추론과 질의응답 task에서 성능이 하락된 것으로 보입니다. (*두 문장의 유사성을 평가하는 데이터셋인 MRPC에서는 유의미한 성능 차이를 보이지 않음)
2) LTR & No NSP
MLM과 NSP를 모두 사용하지 않고, LTR(Left-to-Right) LM을 사용했을 때는 감정 분류 task(SST-2)를 제외하고 모든 task에서 성능이 크게 하락했습니다.
3) LTR + BiLSTM & No NSP
MLM과 NSP를 모두 사용하지 않고, LTR LM 위에 랜덤하게 초기화된 bidirectional LSTM을 추가했을 때는 SQuAD 데이터셋에서 성능 향상이 있긴 했지만(77.8 > 84.9) 여전히 모든 task에서 $BERT_{BASE}$보다 현저히 낮은 성능을 보였습니다.
Fine-tuning BERT
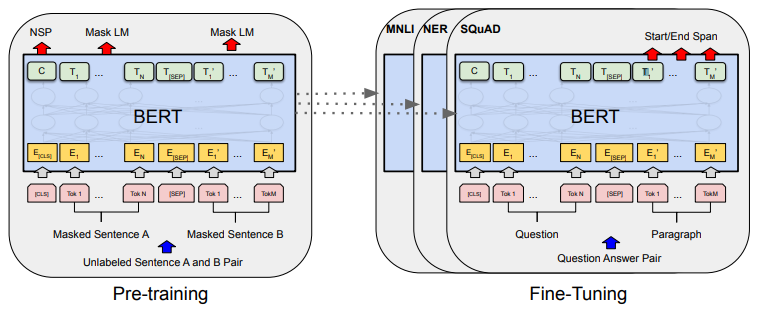
BERT의 강점은 어떤 task든 모델 구조가 거의 동일하다는 것입니다. 위 그림에서 알 수 있듯이 pre-training 모델과 target task 수행을 위한 fine-tuning 모델 간에 차이가 거의 없습니다. fine-tuning 시에 사용한 학습 parameter는 다음과 같습니다.
- batch size 32로 3 epoch 학습
- target task 별로 5e-5, 4e-5, 3e-5, 2e-5 중에서 최적의 learning rate 선택
- 데이터셋이 작은 경우 $BERT_{LARGE}$의 성능이 불안정해서 여러 번 랜덤하게 재시작하고 성능이 가장 좋은 모델을 선택
- 동일한 pre-trained checkpoint 사용
- fine-tuning 데이터셋의 shuffling 달라짐
- classifier layer initialization 달라짐
모델 성능 평가
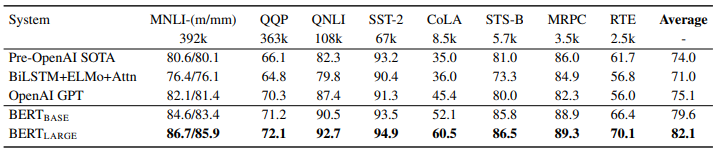
BERT는 11개의 NLP task에서 주요 선행연구들보다 향상된 성능을 보였습니다. 또한 $BERT_{LARGE}$가 $BERT_{BASE}$보다 항상 더 좋은 성능을 나타냈습니다.