BERT, ELMo, GPT-2 모델 비교
ELMo, BERT, GPT-2는 모두 contextualized word representation을 생성하는 모델입니다. contextualized word representation은 단어들이 등장하는 문맥에 따라 서로 다른 vector를 갖습니다. 다의어의 경우 의미에 따라 여러 개의 vector를 갖게 되는 것인데요. 이러한 특성은 문맥에 관계없이 단어 당 하나의 vector만을 갖는 static word embedding과 대조됩니다.
세 모델이 생성하는 word representation의 특성은 동일하지만, 모델 구조 상에는 큰 차이가 있습니다. ELMo는 LSTM 기반 모델이고, BERT와 GPT-2는 transformer 기반 모델이라는 점이 가장 큰 차이점 입니다. 세 모델의 차이점을 간단히 비교해 보면 아래와 같습니다.
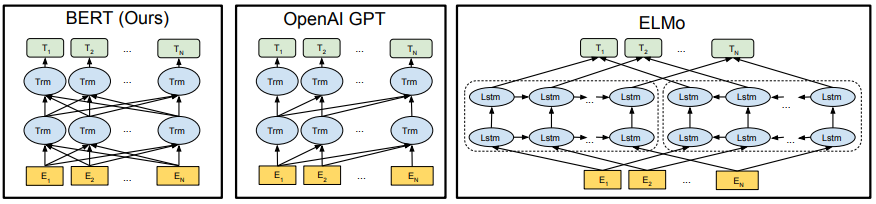
| ELMo | BERT | GPT-2 | |
|---|---|---|---|
| 기본적인 모델 구조 | bidirectional LSTM | Transformer encoder | Transformer decoder |
| pre-trained LM | bidirectional LM | Masked LM & Next Sentence Prediction(NSP) | Multitask Learning 방식으로 학습한 Causal LM |
아래 그래프들은 세 모델의 embedding vector 특성 차이를 비교한 것입니다. 가로 축은 Transformer layer 또는 ELMo의 layer를, 세로 축은 유사도를 나타냅니다.
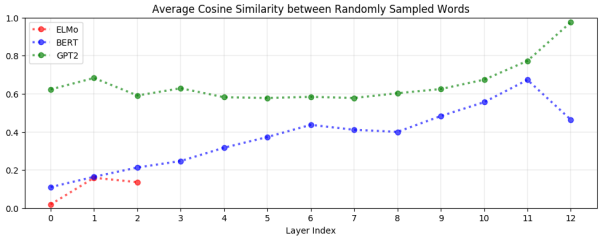
먼저, 위 그래프는 랜덤하게 샘플링한 단어 쌍들의 유사도를 측정한 결과입니다. 이 그래프에서 y축 값이 크다는 것은 단어 간 유사도가 크다는 것으로, 임의의 embedding vector들이 서로 구분되지 않는다는 의미입니다. GPT-2는 모든 layer에서 나머지 모델들보다 높은 유사도를 보이는 반면, ELMo는 가장 낮은 유사도를 보입니다. 또한, BERT와 GPT-2 모두 layer가 깊어질수록 유사도가 높아지는 경향을 확인할 수있습니다.
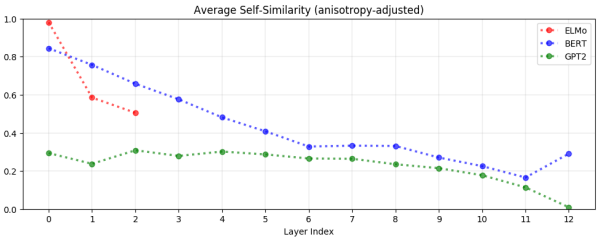
다음으로 위 그래프는 한 단어의 embedding vector을 다른 문맥에서 여러 번 추출했을 때 그 유사도를 측정한 것입니다. 세 모델 모두 layer가 깊어질수록 유사도가 낮아지는 경향을 보입니다. 모든 layer에서 GPT-2의 유사도가 가장 낮게 측정된 것으로 볼 때, GPT-2가 문맥에 따라 embedding vector를 가장 유연하게 바꾼다고 볼 수 있습니다.
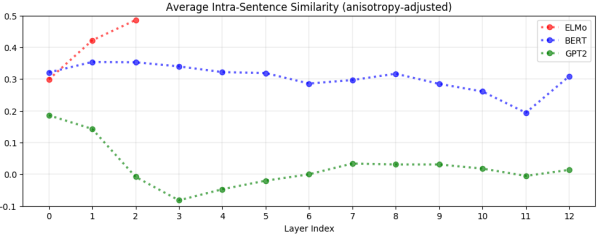
마지막으로 위 그래프는 같은 문장 안의 단어들끼리 유사도를 측정한 결과입니다. y축 값이 너무 높으면 같은 문장 내 단어들이 모두 비슷해진다는 의미로 해석할 수 있습니다. GPT-2는 상대적으로 모든 layer에서 유사도가 낮게 나타나고 있습니다. 이는 GPT-2가 같은 문장 내 단어들도 서로 다르게 embedding한다는 것을 보여줍니다.
위 그래프의 결과를 종합해보면 아래와 같이 정리할 수 있습니다.
- BERT와 GPT-2는 upper layer에서 embedding vector가 서로 비슷해지는 경향이 있음
- ELMo는 lower layer에서는 문맥에 상관없이 일정한 embedding vector를 생성하다가, upper layer에서는 문맥에 따른 서로 다른 embedding vector를 생성함
- GPT-2는문맥에 가장 예민하게 반응하는 모델로, 같은 단어라도 문맥마다 다른 embedding vector을 생성함
- BERT는 문장 내 단어들의 유사도가 적당히 높은 것으로 보아 sentence-level 정보를 잘 유지하고, 문맥에 따라 서로 다른 embedding vector를 생성함