GANs for Image to Image translation
GANs for Image to Image translation
Image-to-Image translation은 주어진 이미지에서 특정한 attribute의 value를 다른 것으로 바꾸는 task를 말합니다. 예를 들어, 성별을 여성에서 남성으로 바꾸거나 얼굴에서 눈썹만 제거하는 것이 여기에 속합니다. 본 포스트에서 등장하는 주요 용어를 정리해보면 다음과 같습니다.
- attribute: 하나의 이미지에 내재된 의미있는 feature ex) 머리 색깔, 성별, 나이
- attribute value: attribute의 특정한 값 ex) 머리 색깔 - black/blond/brown, 성별 - 여성/남성
- domain: 동일한 attribute value를 공유하는 이미지의 집합
1. Conditional GAN (2014)
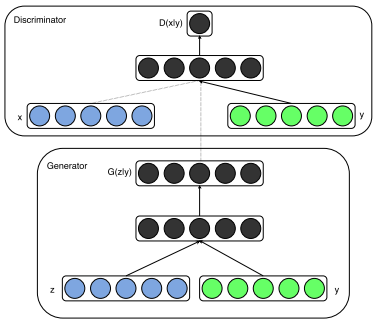 Conditional GAN architecture
Conditional GAN architecture
- 생성하고자 하는 label $y$를 조건으로 입력하는 모델. label $y$는 one-hot encoding 형태로 모델에 입력
- 생성하고자 하는 이미지의 유형을 제어할 수 있음. 예를 들어 성별을 제어하고자 하는 경우, 여성의 얼굴을 생성하려면 $y$에 vector [0, 1]을 입력하고 남성의 얼굴을 생성하려면 [1, 0]을 입력
2. Pix2Pix (2017)
- official code
- conditional GAN을 활용한 image-to-image translation
- conditional GAN의 일종으로, 이미지 $x$ 자체를 조건으로 입력
- 픽셀을 입력받아 픽셀을 예측
- 노이즈 $z$를 사용하지 않기 때문에 거의 deterministic한 결과 생성
- U-Net 사용
- skip-connection
- input과 output은 많은 양의 low-level information을 공유함
- encoder에서 추출한 information을 decoder에서 활용하도록 함으로써 decoder에서는 추가적인 information을 학습하도록 함
- 학습 난이도를 낮춤
- conditional GAN loss와 L1 loss를 함께 사용
- L2 loss이 이미지 간 비교에 적용되면 blurry한 결과가 나올 수 있음(참고)
- 다양한 task에 공통적으로 적용할 수 있는 generic approach
- 한계점
- 서로 다른 domain $X$, $Y$의 데이터들을 한쌍으로 묶은 paired dataset 필요
3. CycleGAN (2017)
- official code
- unpaired image-to-image translation
- 이전 연구인 Pix2Pix처럼 paired dataset이 필요하지 않음. 데이터셋 측면에서의 한계점을 개선
- 원본 이미지 $x$의 content를 유지한 상태로 translation이 가능하다는 보장이 없음
- 어떤 입력 $x$가 주어져도 $x$의 content와 관계없이 taget domain $Y$에 해당하는 하나의 이미지만 출력하면 판별자를 충분히 속일 수 있기 때문
- 추가적인 제약 조건 필요 - $G(x)$가 다시 원본 이미지 $x$로 재구성될 수 있도록 함
- $F(G(x)) \approx x$, $G(F(y)) \approx y$ ($F$와 $G$는 역함수 관계)
- 한계점
- shape 정보를 포함한 content의 변경이 필요한 경우
- 학습 데이터에 포함되지 않은 사물을 처리하는 경우
4. StarGAN (2018)
- 다중 domain에서 효율적인 image-to-image translation network
- 두 개의 domain 간 translation을 위한 방법론을 제안한 CycleGAN의 한계점을 개선
- 하나의 generator만 사용
- CycleGAN을 포함한 기존 연구에서는 다중 domain 간 translation을 수행하기 위해 여러 개의 generator를 중첩해서 사용해야 했음
- $k$개의 domain을 서로 매핑하기 위해 $k(k-1)$개의 generator가 필요함
- 여러 개의 attribute를 한 번에 변경할 수 있음
- 보다 적은 양의 파라미터를 사용
- 다양한 domain의 데이터셋을 활용하여 domain에 관계없이 공통적인 feature를 학습할 수 있음
- 데이터셋
- CelebA - facial attribute transfer (40 labels)
- RaFD - facial expression synthesis (8 labels)
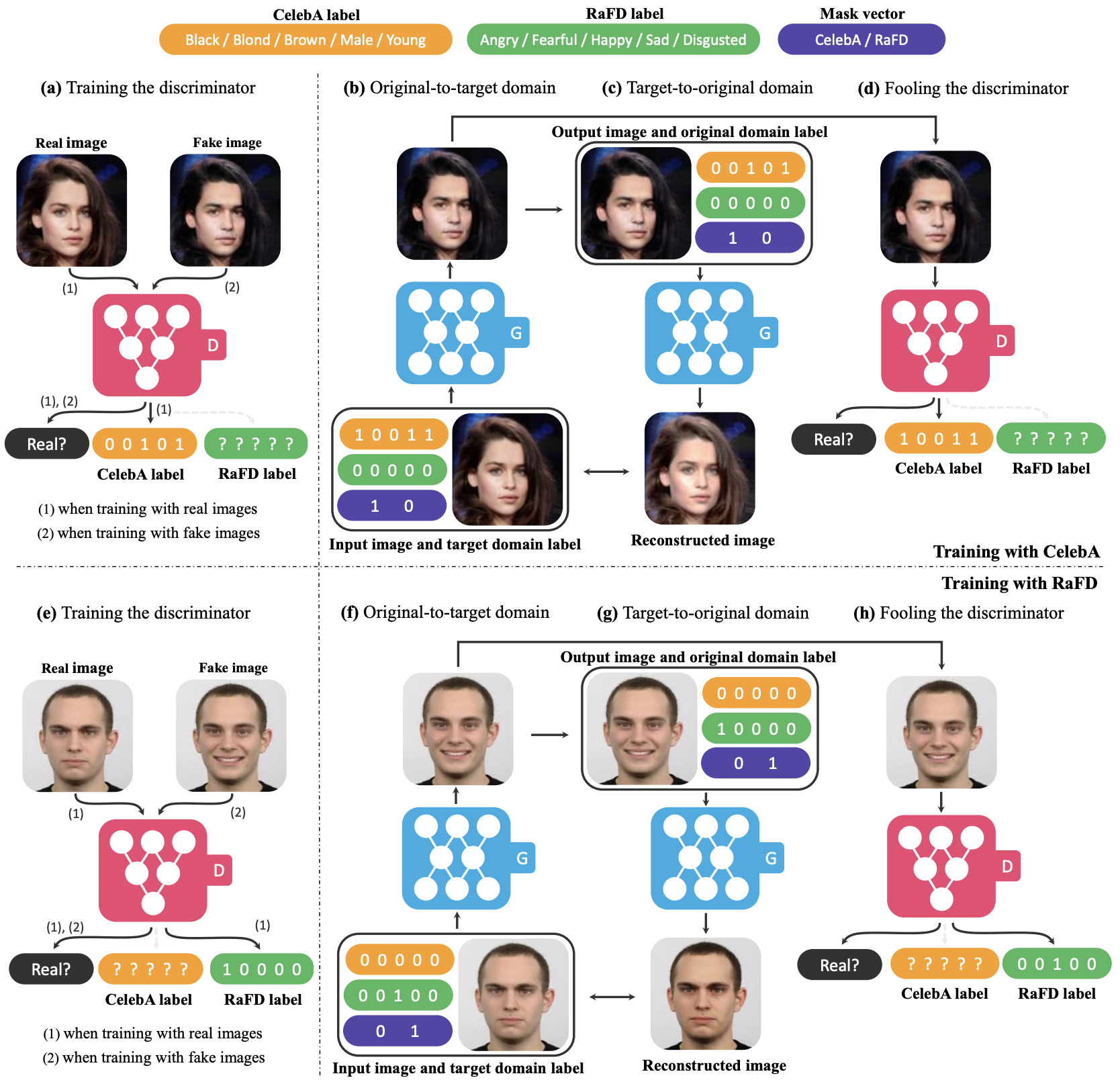
- 모델 구조
- Conditional GAN과 CycleGAN의 구조 활용
- $G(x,c) \rightarrow y$ generator가 input 이미지 $x$를 target domain label $c$로 생성한 output 이미지 $y$
- $D:x \rightarrow { D_{src}(x), D_{cls}(x) }$
- $D_{src}(x)$ input 이미지 $x$가 real인지 fake인지 분류
- $D_{cls}(x)$ input 이미지 $x$가 real이라면 어떤 target domain인지 분류
- 학습 과정
This post is licensed under CC BY 4.0 by the author.