GANs for Single Image Super-Resolution
GANs for Single Image Super-Resolution
Single Image Super-Resolution(SISR)은 한 장의 저해상도 이미지를 고해상도 이미지로 변환하는 방법을 연구하는 분야입니다. 일반적으로, upsampling을 통해 저해상도 이미지의 width, height를 키운 다음, Neural Network에 통과시켜 세밀한 정보를 추가한 고해상도 이미지를 생성합니다. SISR은 학습 방법에 따라 아래와 같이 나누어 볼 수 있습니다. 본 포스트에서는 Unsupervised Zero-Shot SISR 모델 중 SinGAN과 MZSR에 대해 정리해 보겠습니다.
Externally Trained Network (Supervised SISR)
- 다수의 고해상도-저해상도 이미지 쌍을 학습 데이터로 사용합니다.
- 고해상도 이미지로 저해상도 이미지를 만든 다음, 저해상도 이미지를 Neural Network에 입력해서 고해상도 이미지로 복원할 수 있도록 학습을 진행합니다.
Internally Trained Network (Unsupervised Zero-Shot SISR)
- 한 장의 이미지만 학습 데이터로 사용해서 해당 이미지에 특화된 CNN을 학습합니다. 그 이미지에 내재된 feature 정보를 토대로 고해상도 결과를 예측합니다.

- 위 이미지에는 여러 개의 유사한 발코니가 있어서 작은 발코니의 해상도를 높일 때, 큰 발코니를 참고할 수 있는데요. 이러한 경우, 이미지에 자기 반복성(internal recurrence)이 존재한다고 말합니다.
- 여기에서 작은 발코니의 작은 난간과 같은 세부 사항은 외부 데이터베이스에는 존재하지 않는 정보입니다. 이 정보는 오직 같은 이미지 내에서만 발견할 수 있기 때문에, 외부 데이터로만 훈련된 모델로는 해상도를 높이는 데 한계가 있습니다. 이러한 경우에는 외부에서 훈련된 최신 Super-Resolution (SR) 방법보다 이미지의 내부적인 정보가 더 강력한 예측력을 가지고 있습니다. 따라서 이를 효과적으로 활용하는 것이 중요합니다.
- 한계점
- 학습에 사용된 이미지 외의 다른 이미지에 적용하기 어렵습니다.
- 인간의 얼굴처럼 자기 반복성이 떨어지는 경우에도 적용하기 어렵습니다.
1. SinGAN (2019)
- official code
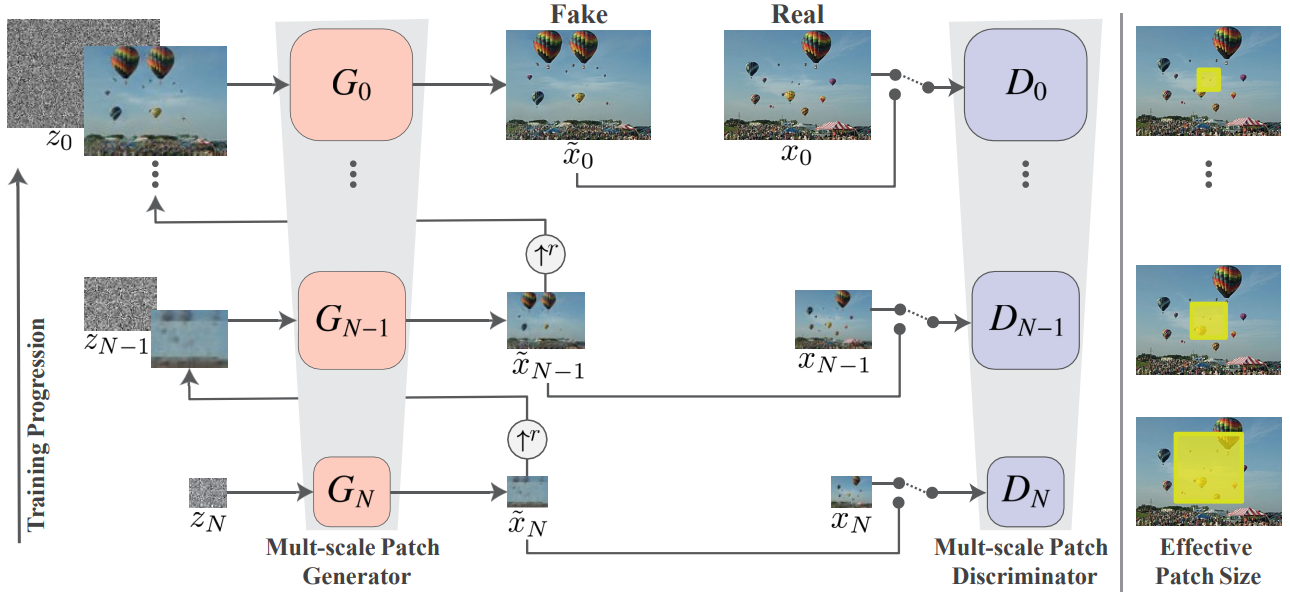
- 한 장의 이미지만을 사용해 GAN 네트워크를 학습
- 총 $N+1$개의 가벼운 개별 GAN 학습
- 생성기
- Residual Learning을 이용해 초반에는 대략적인(coarse) 정보를 추가하고, 점차 세밀한(fine) 정보를 추가
- 생성자는 noise $z_n$와 이전 단계 output $\tilde{x}_{n+1}$을 입력으로 받게 됨
깊은 네트워크를 사용할 수 있음
\[\tilde{x} \ast n=G_n(z_n, (\tilde{x} \ast {n+1}) \uparrow^r)\] \[\tilde{x} \ast n=(\tilde{x} \ast {n+1}) \uparrow^r+\psi_n(z_n+(\tilde{x}_{n+1}) \uparrow^r)\]
- $\psi_n$은 5개의 conv-block으로 이루어진 fully convolutional net
- conv-block 구조: Conv(3X3)-BatchNorm-LeakyReLU
- conv-block별 kernel 개수: 32, 64, 128, 256, 512
- fully convolutional net이기 때문에 테스트 시에 noise map의 모양을 바꿔가면서 다양한 크기와 가로세로비를 갖는 이미지를 생성할 수 있음
- Residual Learning을 이용해 초반에는 대략적인(coarse) 정보를 추가하고, 점차 세밀한(fine) 정보를 추가
판별기는 전체 이미지가 아니라 패치 단위 판별
- 초반에는 패치의 크기가 크고, 점점 패치의 크기가 작아짐. 점진적으로 자세한 정보를 추가
- 생성기
- loss function
- $\underset{G_n}{\min}\,\underset{D_n}{\max}\,\mathcal{L} \ast {adv}(G_n, D_n)+\alpha \mathcal{L} \ast {rec}(G_n)$
- Adversarial loss $\mathcal{L}_{adv}(G_n, D_n)$
- 실제 이미지 $x_n$ 내 패치들의 분포와 $G_n$이 생성한 가짜 이미지 $\tilde x_{n}$ 내 패치들의 분포 사이의 wasserstein 거리가 가깝도록 학습
- Markovian discriminator $D_n$: overlapping된 패치가 real인지 fake인지 분류
- Reconstruction loss $\mathcal{L}_{rec}(G_n)$
- noise map $z$로 실제 이미지 $x$를 정확히 생성하도록 학습
2. Meta-Transfer Learning for Zero-Shot Super-Resolution(MZSR) (2020)
- official code
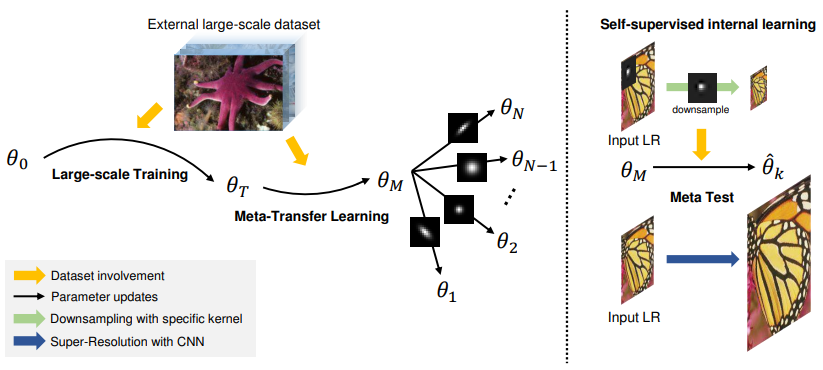
- 한 장의 사진에서 약간의 업데이트(~10회)만을 수행하여 해상도를 복원하는 모델
- 8개의 CNN layer로 구성된 가벼운 모델
- Transfer learning 방식을 사용해 대용량의 외부 이미지에서 학습한 특징 정보를 활용
- Meta learning 방식을 사용해 이미지의 내부 정보를 빠르게 학습할 수 있도록 함
- 각 task별 optimal weight에 빠르게 도달할 수 있는 weight를 찾는 방법인 Model-Agnostic Meta-Learning(MAML) 사용
Reference
This post is licensed under CC BY 4.0 by the author.