[Paper Review] GPT-3: Language Models are Few-Shot Learners
이번 포스트에서는 지난 포스트에 이어 GPT-3(2020)에 대해 다뤄 보려고 합니다. GPT-3는 프롬프트 설계라는 새로운 연구 개발 영역을 개척하고, Large Language Model(LLM) 시대의 서막을 열었다는 점에서 주목할 만한 모델입니다. GPT-3에 대해 자세히 살펴보기에 앞서, 요즘 화두가 되고 있는 LLM의 발전 과정에 대해 간단하게 짚어보겠습니다.
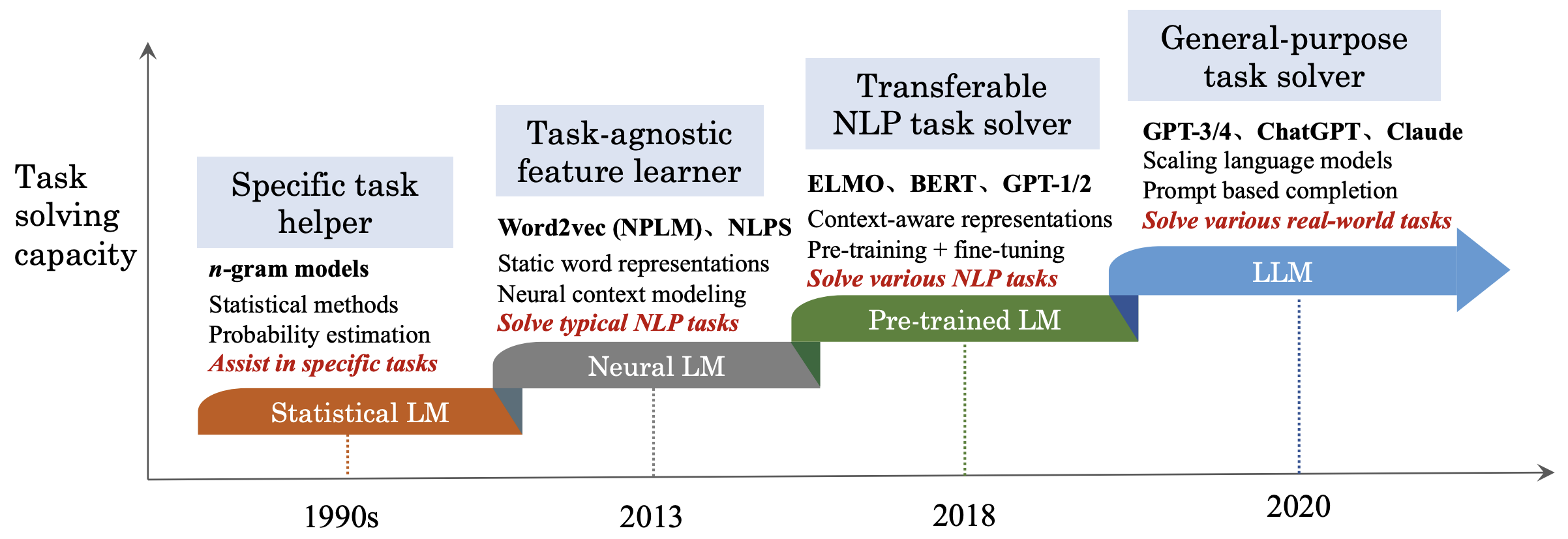
- Statistical LM(1990s) n-gram으로 특정 태스크만 보조
- Neural LM(2013) Word2Vec 계열 static embedding으로 범용 NLP 태스크 해결
- Pre-trained LM(2018) ELMo, BERT, GPT-2가 문맥 기반 단어 embedding을 도입. 대규모 데이터셋으로 pre-train한 모델을 fine-tuning하여 다수의 NLP 태스크에 transfer learning. 여전히 라벨 의존도가 높고, Zero-shot 성능이 낮아 task에 특화된 fine-tuning이 요구됨
- LLM 시대(2020~) GPT-3, GPT-4, Claude 등 거대 모델의 등장. 별도의 fine-tuning 과정 없이, 하나의 foundation model을 학습시키고 태스크별 적절한 프롬프트를 찾아서 적용하는 것이 성능 향상을 위한 필수 요소가 되었음
1. GPT-3의 등장 배경
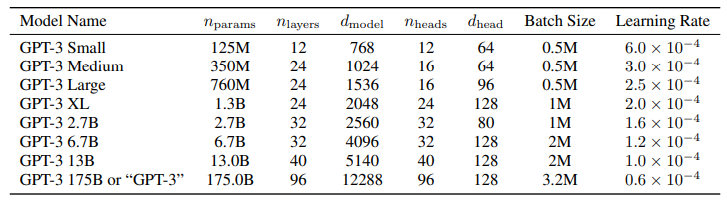
OpenAI는 Scaling Laws for Neural Language Models 논문에서 하이퍼파라미터를 fine-tuning하는 것보다 모델 크기(파라미터 수), 데이터, 연산량을 동시에 확장하는 것이 언어 모델의 성능을 향상시킨다는 사실을 입증했습니다. 해당 논문에서 모델 크기(파라미터 수), 데이터, 연산량과 모델 성능 사이의 관계를 수식으로 일반화한 것이 Scaling Law입니다. OpenAI는 3,000억 개의 토큰으로 이루어진 학습 데이터를 가지고 Scaling Law를 기반으로 다양한 실험을 진행했습니다. 그 결과, 최적의 모델 크기인 1,750억 개의 파라미터를 갖는 GPT-3가 완성된 것입니다.
Scaling Law
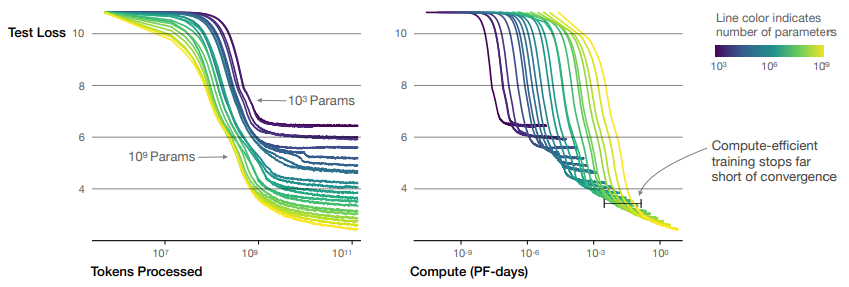
좌측 그래프는 모델이 클수록 같은 성능에 도달하는데 더 적은 수의 토큰를 필요로 함을 보여줍니다. 또한 특정 크기의 모델은 어느 시점부터 loss가 감소하면서 학습이 유의미하게 진행됩니다. 하지만 어느 순간부터는 새로운 토큰을 사용해서 추가 학습을 진행해도 loss가 감소하지 않고 정체합니다. 이를 통해 특정 크기의 모델이 학습할 수 있는 지식의 총량이 제한되어 있음을 알 수 있습니다.
우측 그래프에 따르면, 투입 가능한 계산량이 정해졌을 때 모델 크기와 학습 토큰 수는 최적 값이 정해져 있습니다. 투입 가능한 계산량이 증가함에 따라 최적의 모델 크기, 학습 토큰 수도 증가합니다. 따라서 투입 가능한 계산량이 커진다면, 그에 맞춰 모델 크기와 학습 토큰 수를 늘리는 것이 모델 성능을 높이는데 효과적이라는 것이 저자들의 주장입니다.
2. 학습 데이터
GPT-3는 총 3,000억 개의 토큰을 1 epoch으로 학습했습니다. 단 1 epoch만 학습하는 것은 주어진 학습 데이터에 대한 overfitting이나 학습 데이터를 외워버리는 현상을 막기 위한 목적도 있고, 학습 데이터 자체가 이미 3,000억 개로 충분하기 때문이기도 합니다.
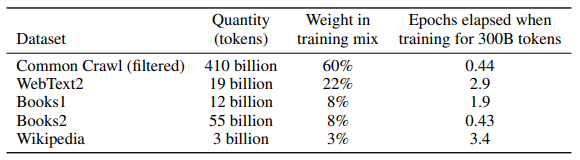 학습 데이터 구성
학습 데이터 구성
학습 데이터 구성표의 Weight in training mix 컬럼을 보면, 고품질 학습 데이터에 더 가중치를 주어 학습에 사용했습니다. Common Crawl 데이터에는 품질이 낮은 데이터가 다수 섞여 있어서, 별도로 학습된 Classifier 사용해 필터링을 수행했습니다.
3. 모델 구조
Pre-LN
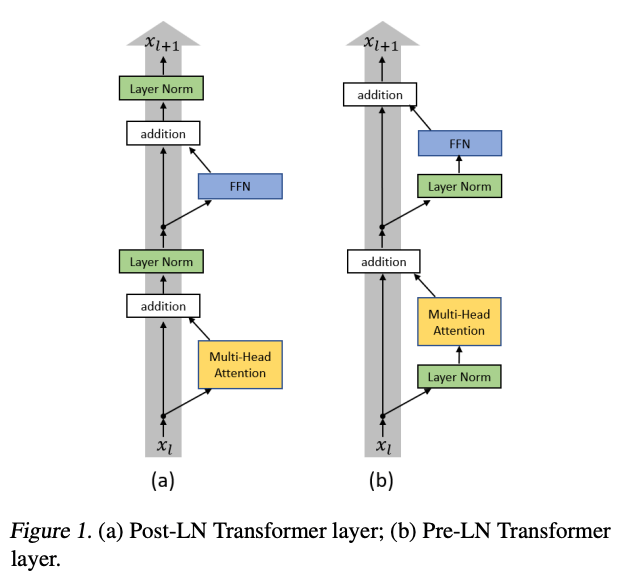
GPT-2와 마찬가지로, Layer Norm의 위치를 변경했습니다. Pre-LN은 Layer Norm이 적용된 값이 residual connection을 통해 더해집니다. 반면, Post-LN은 Layer Norm이 적용되기 전의 값이 residual connection을 통해 더해집니다. Pre-LN은 Post-LN보다 정확도는 다소 낮지만, 학습 안정성이 높다는 장점이 있어 LLM에서 주로 사용됩니다.
Sparse Transformer with fixed attention
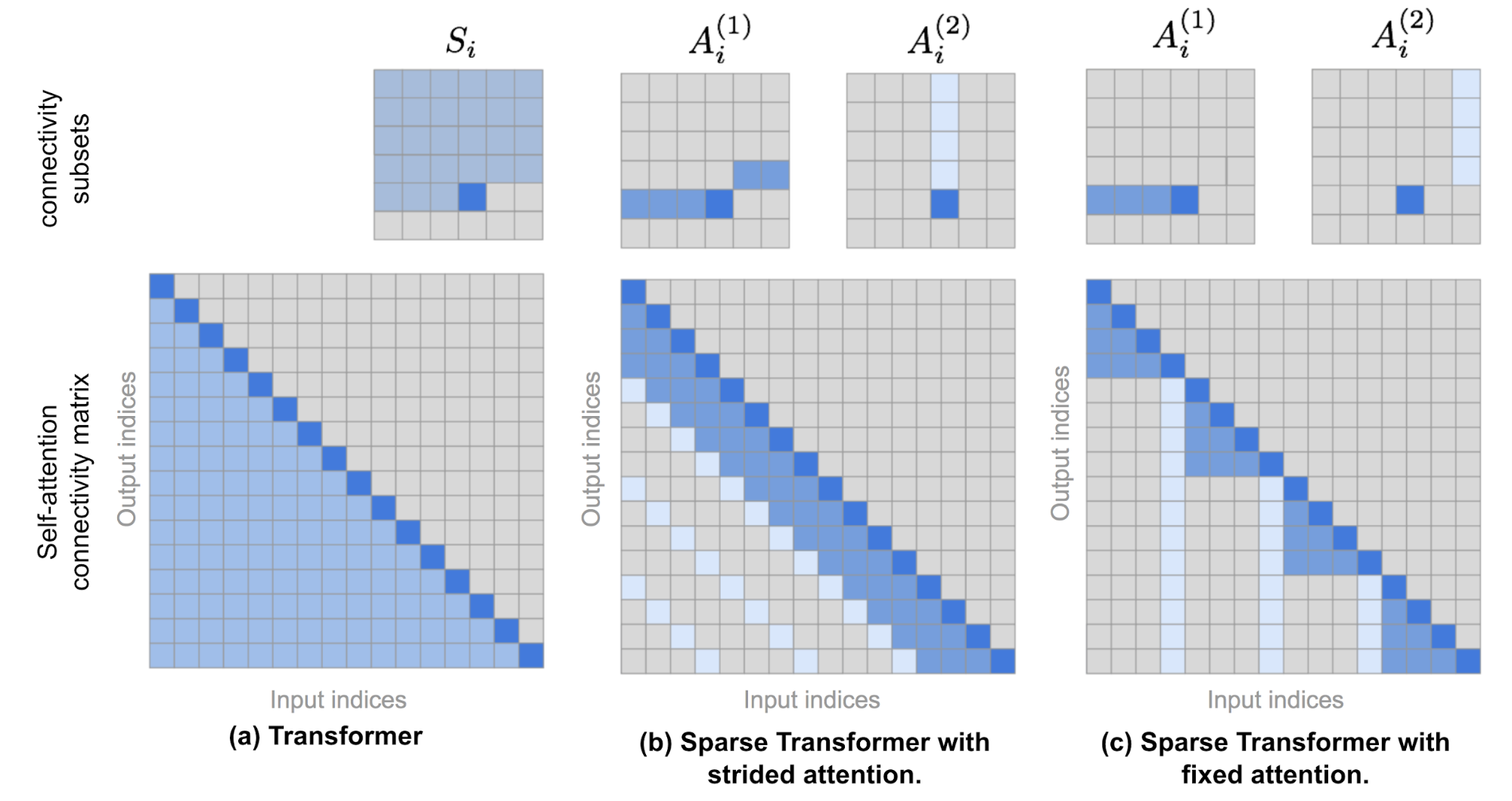
기존 transformer(a)는 sequence 길이 $n$에 대해 복잡도가 $\text{O}(n^2)$입니다. 그래서 입력 sequence $n$이 길어지면 복잡도가 기하급수적으로 증가합니다. 반면, Sparse Transformer(b, c)는 attention mask를 sparse하게 설계하여 전체 $n^2$ 토큰 쌍 중 일부에 대해서만 attetion 연산을 수행합니다. 이에 따라 연산 및 메모리 병목을 대폭 줄일 수 있습니다.
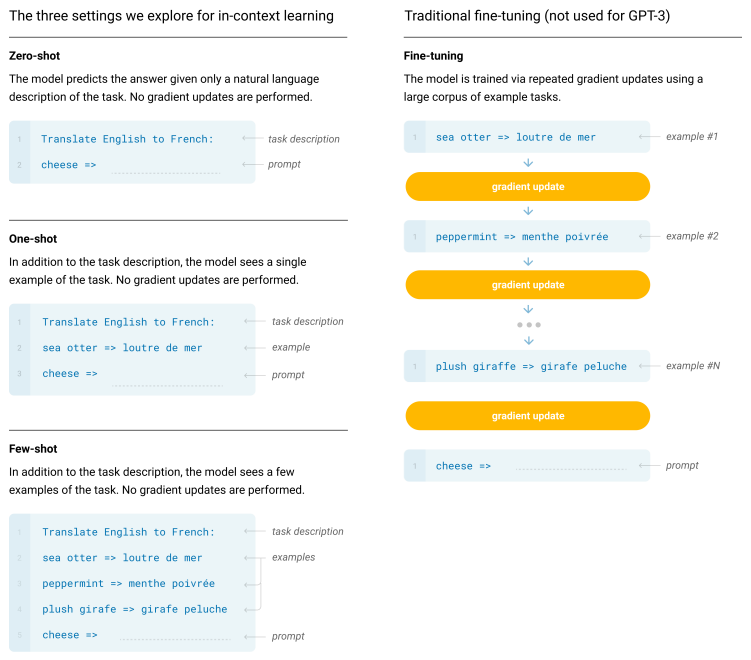
In-context Learning
LLM의 수많은 파라미터를 fine-tuning하는 것은 상당한 연산량과 시간을 필요로 합니다. In-context Learning은 이러한 한계점을 극복하기 위해 LLM fine-tuning의 대안으로 제안된 방법입니다. 저자들은 모델 파라미터를 바꾸지 않고, LLM에 프롬프트를 입력하여 새로운 태스크에 최적화하는 방식을 사용했습니다. 이를 통해 라벨 의존도를 낮추고, fine-tuning의 필요성을 감소시키고자 했습니다.
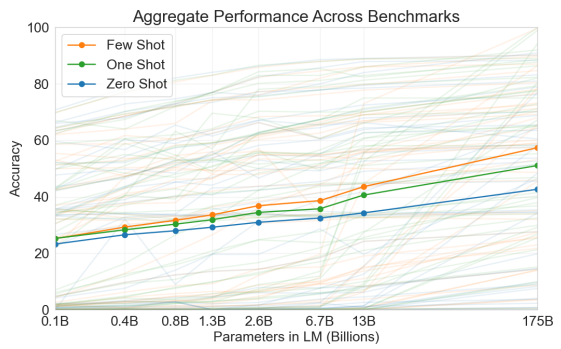
아래 그래프는 모델 크기를 키우면 exmple 수(Few Shot, One Shot, Zero Shot)에 따라 평균 정확도가 어떻게 달라지는지 보여줍니다. 모델이 커질수록 세 경우 모두 평균 정확도가 상승하고, example이 많을수록 그 상승폭이 크다는 점을 확인할 수 있습니다. 특히 모델 크기를 13B에서 175B으로 급격히 증가시켰을 때, 평균 정확도가 가파르게 상승하고 Few Shot, One Shot, Zero Shot 사이의 성능 차이도 눈에 띄게 증가합니다.
4. GPT-2와의 비교
본래는 GPT-2도 fine-tuning 없이 다양한 NLP task에 광범위하게 적용하기 위해 만들어진 모델입니다. 하지만 결과적으로 Zero-shot 성능이 그리 높진 않았고, fine-tuning없이 사용하기에는 부족한 수준이었습니다. GPT-3부터 모델 크기가 175B까지 커지면서 Zero-shot 성능이 눈에 띄게 향상되었습니다.
| 구분 | GPT-2 (2019) | GPT-3 (2020) | 개선 포인트 |
|---|---|---|---|
| 파라미터 | 15 B | 175 B | 10배 이상 확대 → 복잡한 패턴 학습 |
| 학습 데이터 | 40 GB WebText | 400 B+ 토큰 (필터링한 Common Crawl + Books + Wiki) | 도메인 및 언어 다양성 확대 |
| 학습 방법 | Causal LM로 pre-train → fine-tuning | 순수 LM 학습만 수행, 테스트 때 in-context로 task description 및 example 입력 | fine-tuning 비용 및 의존성 제거 |
| 추론 방식 | Zero-shot 성능 제한, fine-tuning 필요 | Few/One/Zero-shot 프롬프트만으로 SOTA 근접 | meta-learning 능력 증가 |