[Paper Review] LLaMA: Open and Efficient Foundation Language Models
LLaMA는 Meta에서 개발한 모델로, “작지만 강한 LLM”이라는 개념을 본격적으로 주목하게 만든 대표 모델입니다. 그 전에도 소형 LLM은 있었지만 성능 면에서 크게 주목받지 못했습니다. 또한 GPT-3를 포함한 대다수의 LLM이 weight를 공개하지 않은 것과 대조적으로, 연구 목적에 한해 모델 weight를 공개한 것도 주목할 만한 점입니다. 이번 포스트에서는 LLaMA가 어떤 모델인지 기술적인 특징과 의미를 자세히 풀어보겠습니다.
1. 등장 배경
GPT-3를 통해, 대규모 데이터셋으로 학습된 큰 크기의 foundation model은 지시문과 몇 개의 예제만으로 새로운 task를 해결할 수 있다는 사실이 입증되었습니다. 하지만 LLaMA의 저자들은 더 많은 데이터를 활용해 작은 모델을 충분히 학습시키면, 큰 모델 못지않은 훌륭한 성능을 달성할 수 있다고 주장합니다. 또한 큰 모델이 목표 성능에 도달하기까지 학습 비용 면에서는 상대적으로 저렴할 수 있지만, 작은 모델은 추론 시에 더 빠르고 저렴하다고 강조합니다. 그래서 GPT-3가 175B까지 모델 크기를 키워 공개한 것과 달리, LLaMA는 7B부터 65B까지 상대적으로 작은 규모의 모델을 공개하며 현존하는 다른 LLM들과의 성능을 비교했습니다.
2. 학습 데이터
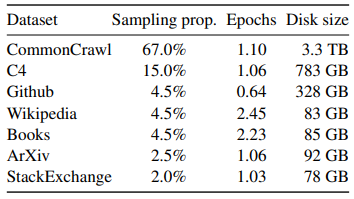
LLaMA 학습에 사용된 데이터셋의 특징은 공개된 데이터셋을 사용했다는 점입니다. 그리고 이전 선행 연구들보다 훨씬 많은 양인, 약 1.4조 개의 토큰을 학습에 사용했습니다.
3. 모델 구조
Pre-normalization
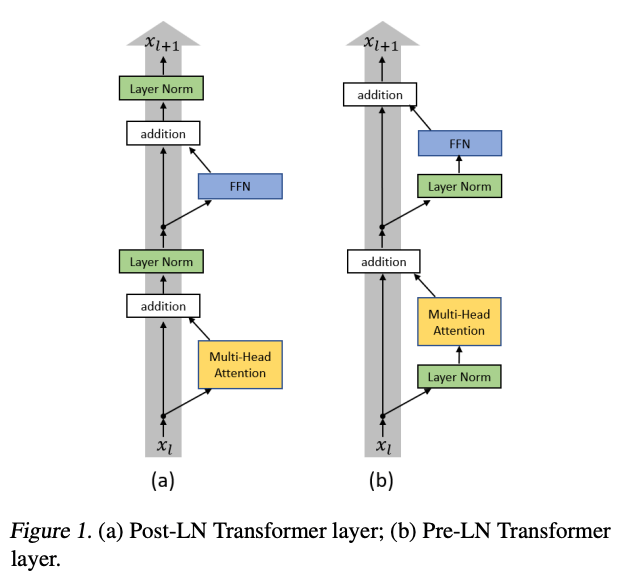
GPT-2, GPT-3와 마찬가지로 Pre-normalization 구조를 사용했습니다. transformer sub-layer의 output을 정규화하는 것이 아니라, input을 정규화하는 구조입니다. 이러한 구조는 학습의 안정성에 도움이 된다고 알려져 있습니다.
SwiGLU activation function
ReLU 대신 SwiGLU activation function을 사용했습니다.
\[\text{ReLU}(x)=\text{max}(0,x)\]ReLU는 입력 값 $x$가 음수이면 0을, 양수이면 그대로 출력합니다.
\[\text{SwiGLU}(x)=\text{SiLU}(xW_{1a}) \times (xW_{1b})\] \[\text{SiLU}(x)=x \cdot \sigma(x)\]SwiGLU는 2개의 선형 변환과 곱셈 연산으로 ReLU보다 더 복잡하고 유연한 표현이 가능합니다.
Rotary Embeddings
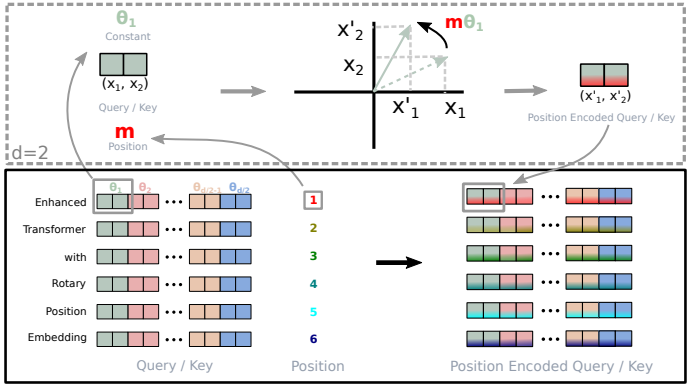
absolute positional embeddings 대신 rotary positional embeddings(RoPE)를 사용했습니다. absolute positional embeddings 방식에서 문장 내 위치가 같은 토큰은 같은 positional embedding vector를 갖습니다. positional embedding vector가 절대적으로 정해져 있는 것입니다. 반면, RoPE는 위치 $m$에 따라 embedding vector를 일정 각도 $\theta$로 회전시켜서 순서 정보를 넣는 방식입니다. 순서가 멀어질수록 회전 각도의 차이가 커져서 토큰 간 상대적 위치를 잘 표현할 수 있습니다.
4. 학습 방법
Optimizer
- AdamW optimizer ($\beta_1=0.9, \beta_2=0.95$)
- cosine learning rate schedule
- weight decay 0.1
- gradient clipping 1.0
- warmup steps 2,000
- batch size와 모델 크기에 따라 learning rate 조정
학습 효율 향상을 위한 방법
- 미래 시점의 토큰을 볼 필요가 없는 causal multi-head attention의 특성을 이용해, attention weight를 저장해두지 않고 각 row마다 바로 $V$와 곱해서 output을 출력
- linear layer의 activation처럼 계산 비용이 비싼 activation만 저장해 두고, 저렴한 연산은 backward 시에 다시 계산
- weight 연산을 여러 GPU에 나눠서 처리 (Model Parallelism)
- sequence를 잘라서 여러 GPU에 나눠서 처리 (Sequence Parallelism)
- 개별 GPU의 계산과 GPU 간 통신을 동시에 진행해서 GPU 사용률을 극대화
5. 실험 결과
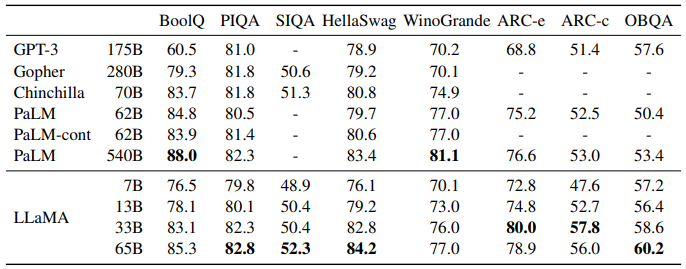
위 표는 Common Sense Reasoning task에서 LLaMA와 다른 LLM들의 성능을 비교한 결과입니다. LLaMA가 상대적으로 작은 모델임에도 크기가 큰 모델과 비슷하거나 더 좋은 성능을 보였습니다.