[Paper Review] Llama 2: Open Foundation and Fine-Tuned Chat Models
오늘 소개할 Llama 2는 Llama 1의 후속 모델로, Llama 1과 마찬가지로 weight가 공개된 모델입니다. Llama 1은 연구 목적에 한해 weight를 받을 수 있었지만 Llama 2는 상업적 사용도 가능해 보다 자유롭게 사용할 수 있습니다. 또한 Llama 1과는 다르게 instruction-tuning이 적용되었습니다. 그 외에 Llama 1과 비교해 어떤 점이 개선되었는지, 모델의 특징과 성능은 어떠한지 자세히 살펴보도록 하겠습니다.
1. 모델 구조
Llama 2도 여느 LLM들과 비슷하게 auto-regressive transformer 구조를 기반으로 만들어졌습니다. 여기에 성능 향상을 위해 몇 가지 사항들을 변경했습니다. 그 중에서도 Grouped-Query Attention(GQA)를 사용한 것이 주목할 만한 변화인데요. 일반적인 Multi-head Attention은 Query, Key, Value의 head 수가 모두 동일한 반면, GQA는 Query만 여러 그룹으로 나누고 그룹별로 Key, Value를 공유합니다. Llama 2-70B 모델의 경우, Query head는 64개, Key/Value head는 8개를 사용합니다. Key, Value의 크기를 줄여서 메모리와 연산량을 크게 절약한 것입니다.
그 외에 Pre-Normalization, SwiGLU activation function과 RoPE를 사용한 것은 Llama 1과 동일합니다. 이 기술에 대한 설명은 지난 포스트에서 확인하실 수 있습니다.
2. Pre-training과 Fine-tuning
Pre-training
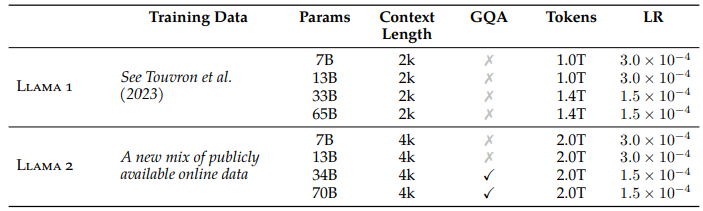
위 표는 Llama 1과 Llama 2의 모델 학습 정보를 비교한 것입니다. Llama 1과 마찬가지로, Llama 2 역시 공개된 데이터만을 사용했고 이들을 새롭게 조합해서 학습용 데이터로 사용했습니다. Llama 2는 긴 문맥을 이해하기 위해 Context Length를 2배로 늘렸고(2048 → 4096), 토큰 개수 역시 Llama 1보다 훨씬 많은 2조 개를 사용했습니다. Tokenizer는 Llama 1과 동일하게 bytepair encoding (BPE) 알고리즘을 사용했습니다.
Fine-tuning
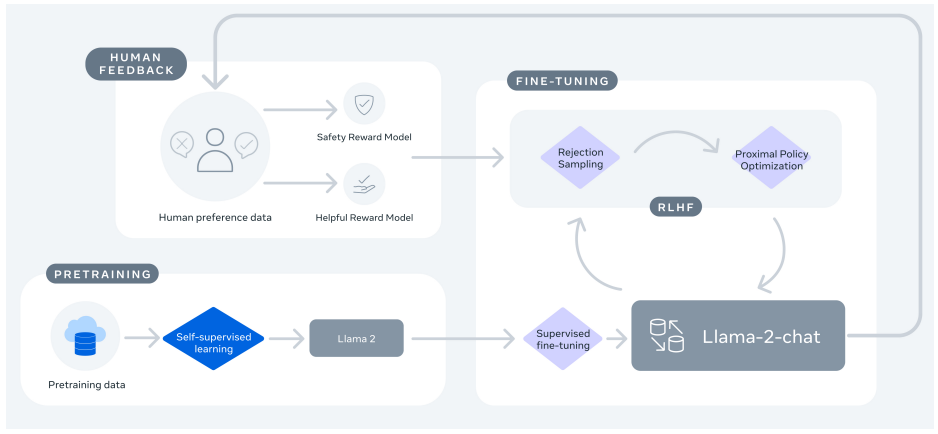
모델 Fine-tuning은 아래와 같이 세 단계를 거쳐 진행됩니다.
Supervised Fine-tuning (SFT): 사람이 만든 Instruction - Output 데이터로 모델을 학습시키는 단계입니다. 모델은 사용자의 지시문을 이해하고, 그 지시에 맞춰 작업을 수행하도록 학습됩니다.Reward Modeling: 같은 질문에 대해 모델이 여러 답변을 생성하면, 사람 평가자가 어느 답변을 선호하는지 수집합니다. 그리고 이 데이터를 사용해서 모델의 답변에 대한 사람의 선호도를 예측하는 Reward Model을 학습합니다. 이 과정을 통해, 모델이 무의미한 문장을 늘어놓거나 공격적인 말투로 답변하지 않고, 고품질의 답변을 생성할 수 있도록 합니다.Reinforcement Learning from Human Feedback (RLHF): Reward Model을 보상 신호로 사용해서 Llama 2를 정책(policy) 처럼 fine-tuning합니다. 아래 손실 함수는 Proximal Policy Optimization (PPO) 알고리즘을 간단히 나타낸 것입니다. 여기에서 $\pi_\theta$는 현재 모델의 확률, $\pi_{old}$는 이전 모델의 확률, $r(y)$는 Reward Model이 준 점수입니다. RLHF를 통해 사람처럼 자연스러운 대화 스타일을 만듭니다.
3. 모델 성능
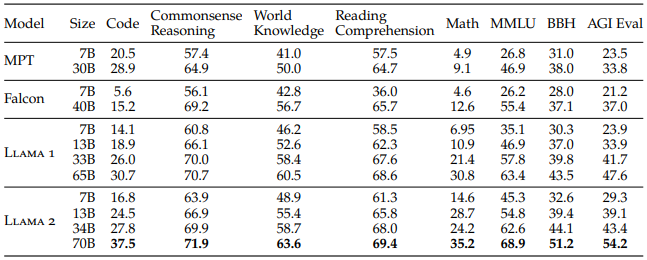
위 표는 전작 Llama 1을 포함한 open-source 모델들과 Llama 2의 benchmark별 성능을 비교한 결과입니다. 비슷한 크기의 모델들을 비교했을 때 Llama 2가 전반적으로 더 좋은 성능을 보였습니다.
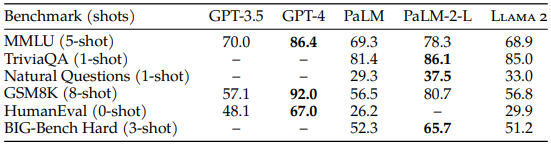
위 표는 closed-source 모델들과 Llama 2 70B 모델의 성능을 비교한 결과입니다. 다방면의 지식을 이해하고 추론하는 능력을 평가하는 MMLU와 수학적 사고력을 측정하는 GSM8K에서는 GPT-3.5와 비슷한 성능을 달성했습니다. 하지만 코딩 능력을 평가하는HumanEval에서는 GPT-3.5보다 현저히 낮은 성능을 보였습니다. 그리고 GPT-4와 PaLM-2-L보다는 모든 영역에서 성능이 낮았지만, PaLM보다는 대체로 우수한 성능을 보였습니다.