[Paper Review] CFA: Coupled-hypersphere-based Feature Adaptation for Target-Oriented Anomaly Localization
CFA는 pre-trained CNN에 patch descriptor와 memory bank를 적용해서 비정상 feature를 더 명확하게 구분할 수 있도록 만든 모델입니다. hypersphere 기반 loss function을 사용해서 patch descriptor를 학습시켜 target 데이터 중심의 feature를 생성하고, target 데이터셋의 크기와 독립적으로 작동하는 memory bank를 사용한 것이 특징입니다. 본 포스트에서는 먼저 이상탐지 분야의 memory bank 기반 접근방법이 갖는 특징과 한계점을 짚어 보겠습니다. 그리고 CFA가 이상탐지를 수행하는 과정을 단계별로 살펴보고, MVTec 데이터셋으로 모델 성능을 평가한 결과를 정리해 보겠습니다.
Memory Bank 기반 접근방법
ImageNet 데이터셋으로 pre-train한 CNN 모델로 feature를 추출하면 target 데이터와 잘 맞지 않는 unfitted feature가 추출될 수 있습니다. mid-level feature를 추출하는 방법도 있지만 근본적인 해결책은 아닙니다. 애초에 두 데이터셋은 분포가 다르기 때문입니다.
기존 방식들은 anomaly localization의 성능을 높이기 위해 memory bank에 최대한 많은 정상 이미지의 feature를 저장하여 사용해 왔는데요. memory bank에 많은 양의 unfitted feature가 있으면 비정상 feature의 정상성을 과대평가할 가능성이 있습니다. 어떤 test 이미지가 이 feature들과 거리가 가깝다고 하더라도, 분석 대상 데이터에 해당하는 정상 feature가 아니기 때문에 해당 이미지가 정상이라고 보기는 어렵습니다. 즉, 이 feature들이 memory bank에 다수 존재함으로써 부정확한 정상성 정도가 산출되는 것입니다.
CFA는 이러한 문제를 해결하고자 pre-trained CNN을 통해 추출한 feature를 그대로 사용하지 않고, target 데이터에 대한 adaptation을 수행합니다. ImageNet 데이터셋에 편향되지 않고 target 데이터에 최적화된 feature를 학습해 사용하는 것입니다.
이상탐지 진행 과정
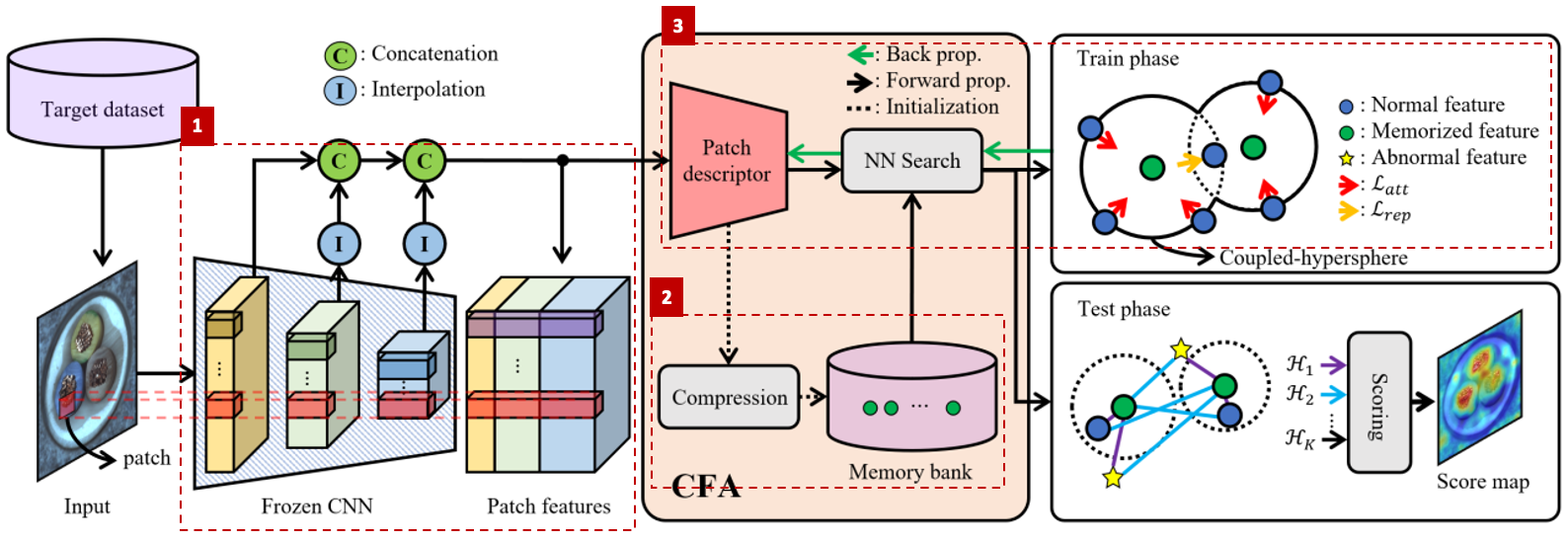
1. Patch feature 생성
ImageNet 데이터셋으로 pre-train한 CNN 모델에 정상 이미지를 통과시켜 feature를 추출합니다. 그리고 block별 feature에 interpolation을 취해 크기를 맞춰준 다음, concatenate 합니다. 이렇게 생성된 patch feature $p_t$는 해당 위치의 semantic information을 담고 있습니다.
2. Memory bank 생성
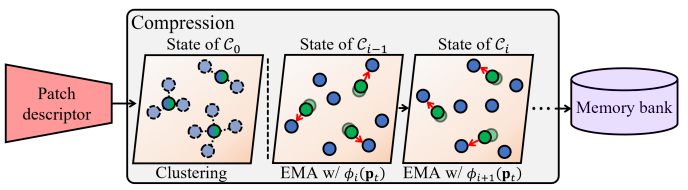
위 그림은 학습 데이터셋의 이미지들을 하나씩 거치면서 Memory bank를 구성하는 과정을 보여줍니다. 초록색 동그라미는 이전 시점의 Memory bank를 나타내고, 파란색 동그라미는 현재 시점의 정상 이미지로부터 얻은 patch feature를 나타냅니다.
[State of $C_0$] 학습 데이터셋의 첫 번째 정상 이미지 $x_0$로부터 얻은 모든 patch feature들 $\phi_0(p_{t \in { 1, …, T }})$로 K-means clustering을 수행해서 초기 memory bank $C_0$를 구성합니다.
[State of $C_{i}$] 이전 시점 memory bank $C_{i-1}$에서 $i$번째 정상 이미지 $x_i$로부터 얻은 patch feature들과 가장 가까운 feature들 $C_{i}^{NN}$을 찾고, $C_{i}^{NN}$과 $C_{i-1}$의 가중 평균(exponential moving average, EMA)으로 memory bank $C_{i}$를 업데이트합니다.
\[\mathcal{C}_{i} \leftarrow (1-\beta) \cdot \mathcal{C}_{i-1}+ \beta \cdot \mathcal{C}_{i}^{NN}\]- 이 과정을 학습 데이터셋의 크기만큼 반복해서 memory bank를 완성합니다.

학습 데이터셋 크기와 관계없이 일정한 크기의 Memory bank가 점차 업데이트 된다는 것을 알 수 있는데요. 이 점이 CFA가 선행연구들과 차별화되는 점입니다.
3. Patch feature 업데이트
정상 patch feature $\phi(p_t)$가 memory bank 내 memorized feature 중 최근접 이웃 $c_t^k$와 가까이에 위치하도록 업데이트합니다.
\[\mathcal{L}_{att}=\frac{1}{TK}\sum_{t=1}^T\sum_{k=1}^Kmax\{ 0,\mathcal{D}(\phi(p_t),c_t^k)-r^2 \}\]하지만 동시에 여러 hypersphere에 포함되는 모호한 $\phi(p_t)$가 존재하면 비정상 feature의 정상성을 과대평가할 여지가 있습니다. 따라서 추가적으로 hard negative feature를 사용하는데요. $\phi(p_t)$가 $K+j$ 번째 최근접 이웃 $c_t^j$와는 멀어지도록 업데이트 하는 것입니다.
\[\mathcal{L}_{rep}=\frac{1}{TJ}\sum_{t=1}^T\sum_{j=1}^Jmax\{ 0,r^2-\mathcal{D}(\phi(p_t),c_t^j)-\alpha \}\]두 loss를 더한 값을 최종 loss로 사용했고, 본 논문에서 사용한 하이퍼 파라미터는 다음과 같습니다.
\[\mathcal{L}_{CFA}=\mathcal{L}_{att}+\mathcal{L}_{rep}\]- $K=3$
- $J=3$
- $r=1e-5$
- $\alpha=1e-1$
모델 성능 평가
