[Paper Review] ELMo: Deep contextualized word representations
Introduction
대용량 corpus로 사전 학습한 단어 embedding vector를 사용하는 것은 이제 NLP 모델의 표준으로 자리 잡았습니다. 이 vector들이 문맥상 단어의 의미와 문장 구조에 대한 정보를 잘 함축하고 있기 때문입니다. 이에 따라 NLP 분야의 많은 연구자들이 모델 성능 향상을 위해 고품질의 단어 embedding vector를 구하는 방법을 연구해 왔는데요. 전통적인 방법들은 단어당 하나의 embedding(static word embedding) vector밖에 구할 수 없다는 한계가 있었습니다.

위 이미지에서 GloVe를 통해 구한 play의 embedding vector와 가장 가까이에 이웃한 단어들은 스포츠 경기와 관련된 단어들에 한정되어 있습니다. 반면에 biLM(bidirectional language model)을 사용해서 구한 embedding vector는 문맥에 따라 최근접 이웃 단어가 다릅니다. 이처럼 어떤 단어가 문맥 상 다른 의미를 가질 때, 단어의 의미에 따라 서로 다른 embedding vector를 효과적으로 구할 수 있는 모델이 본 논문에서 제안하는 ELMo입니다.
ELMo: Embeddings from Language Models
Bidirectional language models
forward LM이 $N$개의 단어($t_1, t_2, …, t_N$)로 이루어진 squence의 확률을 계산하는 방법은 다음과 같습니다.
\[p(t_1, t_2,...,t_N)=\prod_{k=1}^Np(t_k|t_1, t_2,...,t_{k-1})\]backward LM은 주어진 sequence를 거꾸로 훑는다는 점만 다릅니다.
\[p(t_1, t_2,...,t_N)=\prod_{k=1}^Np(t_k|t_{k+1}, t_{k+2},...,t_N)\]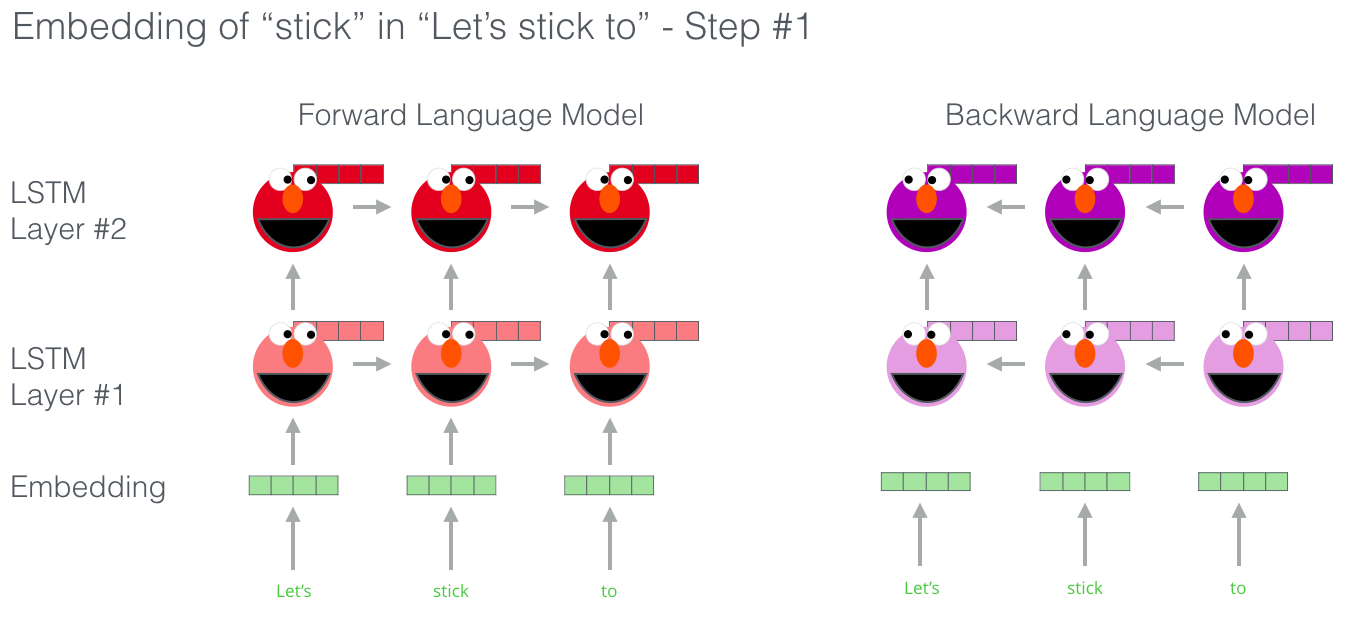
다시 말해, forward LM은 $k$ 이전 시점의 단어들($t_1, t_2,…,t_{k-1}$)이 주어졌을 때 $t_k$의 확률을 모델링하고, backward LM은 반대로 $k$ 이후 시점의 단어들($t_{k+1}, t_{k+2},…,t_N$)이 주어졌을 때 $t_k$의 확률을 모델링합니다. biLM은 forward LM과 backward LM을 결합한 모델이고, 본 논문에서는 LM로 LSTM을 사용했습니다.
위 수식을 살펴보면 forward LSTM과 backward LSTM의 파라미터들 $\Theta^\rightarrow_{LSTM}$, $\Theta^\leftarrow_{LSTM}$은 분리하고, 단어 embedding vector와 Softmax layer의 파라미터 $\Theta_x$, $\Theta_s$는 공유한다는 것을 알 수 있습니다.
ELMo
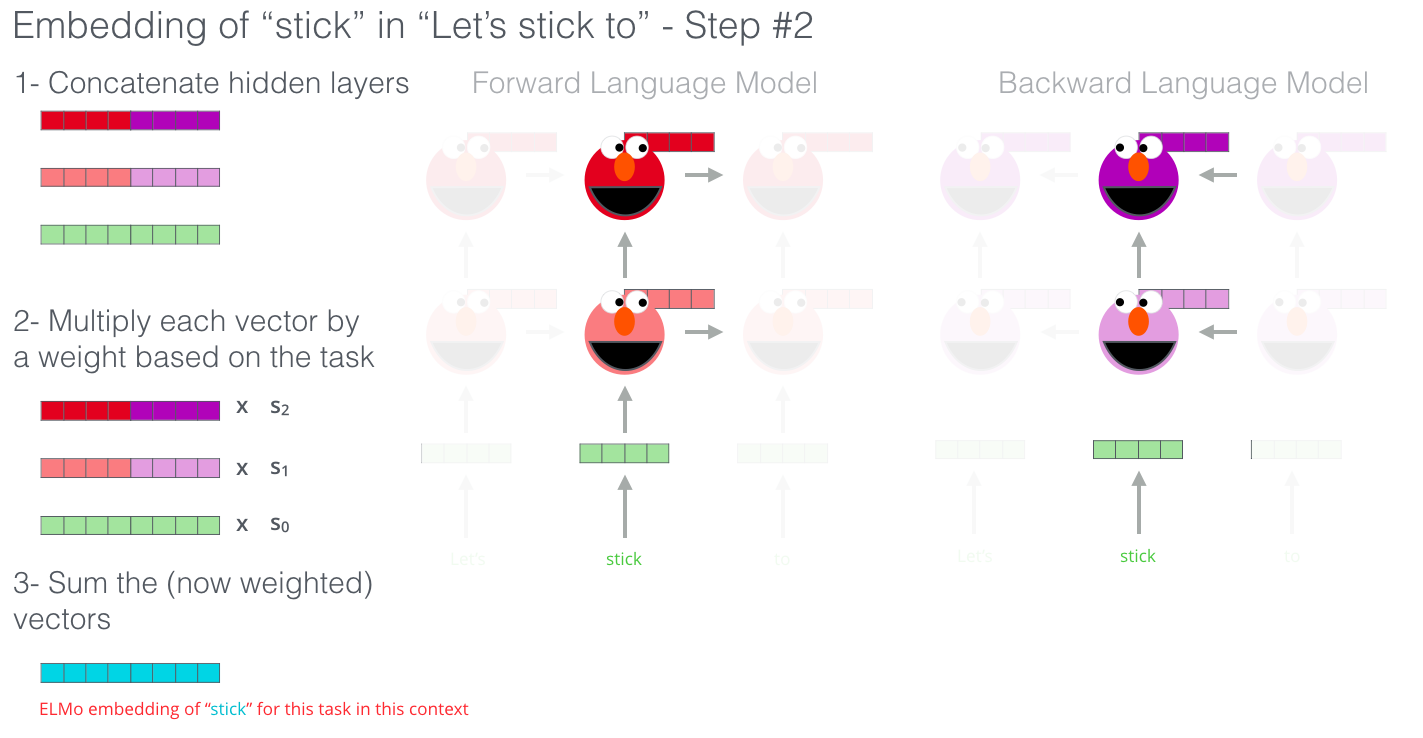
ELMo는 bidirectional LSTM을 대용량 데이터로 학습시켜 특정 문맥 상 단어의 embedding vector를 구합니다. 위 이미지를 보면, biLM의 여러 layer에서 구한 vector들의 linear combination으로 stick의 최종 ELMo embedding vector(하늘색)를 구한다는 것을 알 수 있습니다. $L$개의 layer로 특정 단어 $t_k$의 ELMo embedding vector를 구하는 수식으로 나타내면 다음과 같습니다.
\[ELMo_k^{task}=E(R_k;\Theta^{task})=\gamma^{task}\sum_{j=0}^{L}s_j^{task}\mathbf{h}_{k,j}^{LM}\]위 수식에서 $j=0$이면 embedding layer를 가리킵니다. 이 layer에 입력되는 단어 embedding vector $x_k$는 문맥에 관계없이 사전 학습된 context-independent vector입니다. 반면, $x_k$가 biLM을 거쳐 산출된 output인 ELMo embedding vector는 문맥에 대한 정보가 함축된 context-dependent vector입니다.
$\gamma^{task}$와 $s^{task}$도 학습 과정에서 업데이트되는 파라미터인데요. $\gamma^{task}$는 ELMo embedding vector 전체를 스케일링합니다. $s^{task}$는 softmax-normalized 가중치로, task의 성격에 따라 biLM layer 각각에 서로 다른 가중치를 부여하는 역할을 합니다. 예를 들어, target task가 syntactic parsing이나 POS tagging이면, 문장 구조에 대한 이해가 필요하므로 아래쪽 layer의 가중치가 높아질 것이고, semtiment analysis와 같이 문맥에 대한 이해가 필요한 task이면 위쪽 layer의 가중치가 높아질 것입니다. 또한 각각의 biLM layer는 각기 다른 분포를 가지고 있기 때문에, $s^{task}$를 곱하기 전에 $\mathbf{h}_{k,j}^{LM}$에 layer normalization을 적용하는 것이 성능 향상에 도움이 된다고 합니다.
이러한 방식을 사용하면 맨 위 LSTM layer만 사용하는 것보다 훨씬 풍부한 deep representation을 구할 수 있습니다. 위쪽 layer는 문맥을 고려한 문장 내 단어의 의미를 모델링하고, 아래쪽 layer는 문장 구성 및 구조를 모델링하는 특징이 있는데, 두 가지 특징을 모두 반영할 수 있기 때문입니다. 위에서 언급한 바와 같이, forward LSTM과 backward LSTM은 독립적으로 학습합니다.
Using biLMs for supervised NLP tasks
ELMo는 target task를 수행할 때, 이렇게 사전 학습한 ELMo embedding vector를 업데이트하지 않고 추가적인 feature로써 사용합니다. 구체적으로 설명하면, 단어 embedding vector $x_k$와 ELMo embedding vector $ELMo_k^{task}$를 이어 붙인 $[x_k;ELMo_k^{task}]$를 task RNN에 입력합니다. 또한 저자들의 실험에 따르면, 일부 task들에 대해서는 task RNN의 output $h_k$에도 $ELMo_k^{task}$를 이어 붙여서 $[h_k;ELMo_k^{task}]$을 사용하면 성능이 더욱 향상된다고 합니다. 이러한 방식은 feature-based 방식으로 볼 수 있으며, OpenAI GPT가 사용하는 fine-tuning 방식과 대조됩니다.
Pre-trained bidirectional language model architecture
논문에서 사용한 모델 구조는 다음과 같습니다.
- 2-layer biLSTM (4096 units, 512 dimension projections)
- layer 간 residual connection 사용
character convolutions을 통해 subword 정보를 함축한 단어 embedding vector $x_k$를 구함- character embedding > convolutional layer > max pool layer > 2-layer highway network > linear projection으로 512 차원으로 축소
- kim et al. (2015) 모델 구조 참고 (완전히 동일하지 않음)
