[Paper Review] GPT-2: Language Models are Unsupervised Multitask Learners
Introduction
NLP 모델을 개발할 때, 일반적으로 unlabeled 데이터셋은 충분하지만 특정 task를 학습시키기 위한 labeled 데이터셋은 부족하다는 문제가 있습니다. GPT-1은 이 문제를 해결하기 위해 unsupervised pre-training과 supervised fine-tuning을 결합하여 사용하는 semi-supervised learning 방식을 사용합니다. 따라서 대용량의 unlabeled 데이터셋과 target task를 학습할 적당량의 labeled 데이터셋이 있을 때 사용 가능한 모델입니다. 이 때, 두 데이터셋의 domain은 같지 않아도 무방합니다. GPT-1는 이러한 과정을 통해 약간의 adaptation만으로 다양한 task에 적용할 수 있는 범용적인 representation을 학습하고자 했습니다.
하지만 fine-tuning을 수행할 때 모델은 데이터 분포의 미세한 변화에 민감할 수밖에 없습니다. 또한 결과적으로 target task에 특화된 모델을 학습하게 됩니다. 일반화 성능이 떨어진다는 한계점이 여전히 남아 있는 것입니다. 후속 논문(Radford et al., 2018)에서 저자들은 하나의 domain 데이터셋으로 하나의 task를 학습하는 구조가 일반화 성능을 저해하는 주요 요인임을 지적했습니다. 그리고 Multitask Learning을 통해 fine-tuning에 대한 의존성을 크게 낮춘 모델인 GPT-2를 제안했습니다. GPT-2의 모델 구조는 GPT-1과 거의 동일합니다.
본 포스트에서는 GPT 모델 구조의 특징을 자세히 살펴보고, GPT-1에 비해 GPT-2에서 개선된 점은 무엇인지 알아보겠습니다.
GPT-1
모델 구조
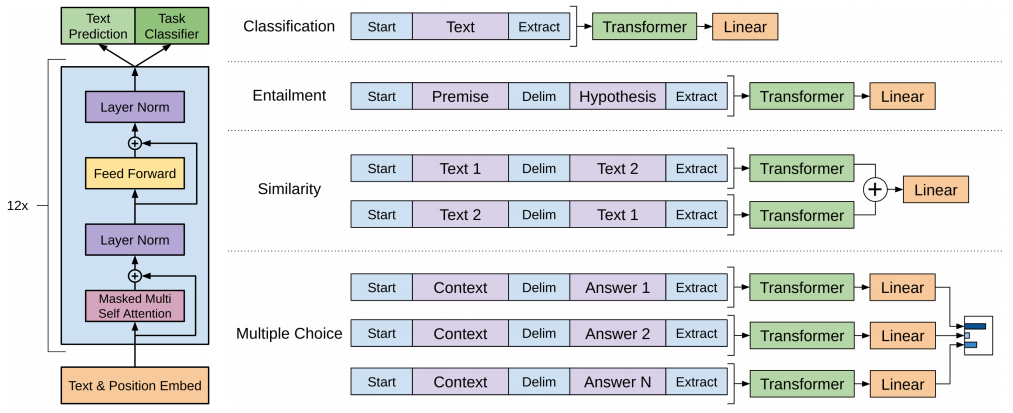
GPT-1과 대표적 선행 연구인 ELMo는 모델 구조 및 사전 학습한 word representation을 사용하는 방식에서 차이가 있습니다. 먼저 ELMo는 bidirectional LSTM 기반 모델인 반면, GPT-1은 12개의 Transformer decoder layer를 쌓아 만든 모델입니다. 또한 ELMo는 target task를 수행할 때, 사전 학습한 word representation을 업데이트하지 않고 추가적인 feature로써 사용하는데요. GPT-1은 target task에 특화된 파라미터를 최소화해서, target task를 수행할 때 사전 학습한 모든 파라미터를 fine-tuning합니다.
위 이미지와 같이, task 별로 변형된 input이 사전 학습된 Transformer에 입력되고 Transformer의 output은 linear+softmax layer에 입력됩니다. task별 입력 구조의 차이(task-aware input transformations)로 인해 모델 구조에 약간의 차이가 있지만, 대체로 동일한 구조를 갖습니다.
BERT uses a denoising self-supervised pre-training task, while the GPT line of work uses language modeling as its pre-training task
학습 과정
Unsupervised pre-training
먼저 language model로 대용량 unlabeled 데이터셋 $\mathcal{U}= { u_1,…,u_n }$를 학습합니다.
\[L_1(\mathcal{U})=\sum_i\log P(u_i|u_{i-k},...,u_{i-1}; \Theta)\]이 때, LSTM을 사용하면 장기 예측이 어렵다는 한계가 있기 때문에 Transformer decoder를 사용했습니다.
\[h_0=UW_e+W_p\] \[h_l=transformer\_block(h_{l-1})\forall i \in [1, n]\] \[P(u)=softmax(h_nW_e^T)\]Supervised fine-tuning
다음으로는 supervised model로 labeled 데이터셋 $\mathcal{C}$를 학습하여 fine-tuning을 수행합니다. 이 때, 데이터셋 $\mathcal{C}$의 데이터들은 일련의 토큰들 $x^1,…,x^m$과 해당 sequence의 label $y$로 이루어져 있습니다.
\[p(y|x^1,...,x^m)=\text{softmax}(h_l^mW_y)\] \[L_2(\mathcal{C})=\sum_{(x,y)}\log P(y|x^1,...,x^m)\]또한 labeled 데이터셋 $\mathcal{C}$에 대해서 target task뿐만 아니라, language model도 학습해서 objective function에 포함시켰는데요. 저자들의 주장에 따르면, objective function을 이렇게 구성하면 supervised model의 일반화 성능이 향상되고 수렴도 더 빠르다고 합니다.
\[L_3(\mathcal{C})=L_2(\mathcal{C})+\lambda*L_1(\mathcal{C})\]모델 성능 평가
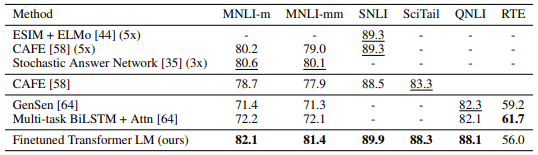 Results on natural language inference
Results on natural language inference
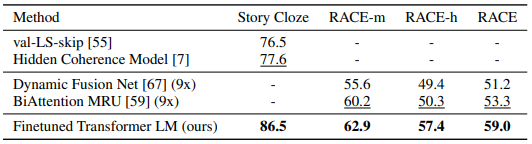 Results on question answering and commonsense reasoning
Results on question answering and commonsense reasoning
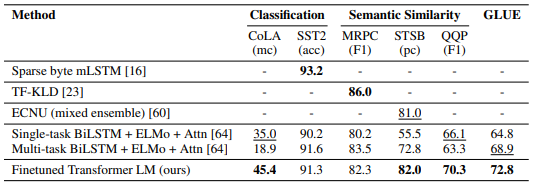 Results on classification and semantic similarity
Results on classification and semantic similarity
GPT-1(위 표에서는 Finetuned Transformer LM으로 표기)은 대부분의 데이터셋에서 ELMo를 포함한 선행 연구들보다 뛰어난 성능을 나타냈습니다.
GPT-2
등장 배경
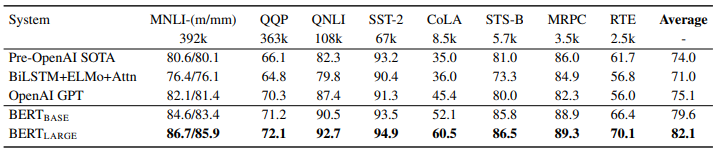 BERT 실험 결과
BERT 실험 결과
GPT-1 이후 등장한 BERT는 대부분의 NLP task에서 최고의 성능을 보였습니다. 하지만 BERT 역시 GPT-1처럼 fine-tuning 과정이 필요한 모델입니다. GPT-2는 모델 사이즈와 학습 데이터 양을 크게 증가시켜 fine-tuning 의존성을 크게 낮춘 범용 모델을 제안합니다.
학습 데이터셋
Introduction에서 언급한 바와 같이, GPT-2는 Multitask Learning방식을 사용합니다. 이 때문에 조건부 확률 $p(\text{output} \vert \text{input})$을 추정하는 것이 아니라, $p(\text{output} \vert \text{input}, \text{task})$를 추정하는 문제가 됩니다.

선행연구들과 GPT-2에서 pre-training 시 사용한 데이터셋을 비교해보면 다음과 같습니다.
| Model | Dataset | Type | Size |
|---|---|---|---|
| ELMo | 1B Word Benchmark(Chelba et al., 2014) | shuffled senetence-level | 30 million sentences and 1B words |
| GPT-1 | BooksCorpus(Zhu et al., 2015) | document-level | 11,038 books (around 74M sentences and 1G words) of 16 different sub-genres |
| BERT | BooksCorpus(Zhu et al., 2015) & English Wikipedia | document-level | BooksCorpus 800M words English Wikipedia 2500M words |
| GPT-2 | WebText | document-level | Over 8 million documents for a total of 40 GB of text *All Wikipedia doments are removed |
The key insight was that the model continued to get more and more accurate as it became bigger, reaching state of the art. This might seem unsurprising, but other language models, such as BERT, start to become less accurate at a certain point in data size.
GPT-1과의 비교
layer normalization의 위치 변경 (Pre-LN)
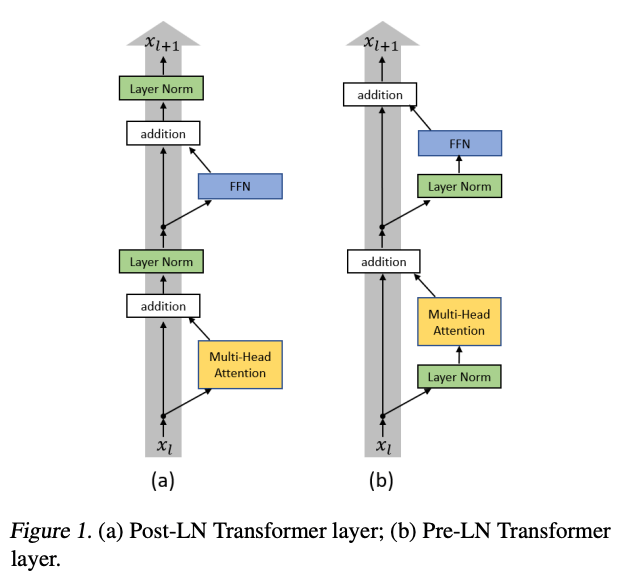
- 마지막 self-attention block 뒤에 layer normalization 추가
- initialization 변경
- residual layer의 가중치 스케일링 (스케일링 팩터는 $\frac{1}{\sqrt{N}}$이고, $N$은 residual layer의 개수)
- vocabulary size를 50,257로 확장
- context size를 512개의 토큰에서 1024개의 토큰으로 증가시킴
- batch size로 512 사용
모델 성능 평가
 Zero-shot results
Zero-shot results
GPT-2는 zero-shot task에서 8개의 데이터셋 중 7개에 대해 선행연구들보다 뛰어난 성능을 나타냈습니다. 1BW(1B Word Benchmark, ELMo pre-training에 사용된 데이터셋)에서는 낮은 성능을 나타냈는데요. 1BW에서는 문장들의 순서가 랜덤하게 섞여있어 문장 간 의존성이 없기 때문이라고 볼 수 있습니다.
Because the original data had already randomized sentence order, the benchmark is not useful for experiments with models that capture long context dependencies across sentence boundaries.