[Paper Review] QLoRA: Efficient Finetuning of Quantized LLMs
LLM을 fine-tuning하는 것은 성능 향상에 효과적인 방법이긴 하지만 너무 큰 비용이 요구되어 현실적으로 제약이 많습니다. 이러한 이유로 LLM을 효과적으로 fine-tuning하는 방식인 LoRA가 제안되었는데요. LoRA는 모델 전체를 fine-tuning하는 것보다 훨씬 적은 양의 메모리와 학습 시간을 사용하면서도 비슷한 수준의, 혹은 그 이상의 성능을 달성했습니다.
이번 포스트에서는 LoRA보다도 더 적은 자원으로 LLM을 fine-tuning할 수 있는 QLoRA(2023)에 대해 알아보겠습니다. QLoRA는 LoRA처럼 저차원 보조 행렬을 사용하는데, 여기에 양자화 개념을 더한 방식입니다. 조금 더 구체적으로 설명하면, 먼저 pretrained LLM을 4bit 양자화해서 freeze한 뒤, 저차원 보조 행렬만 학습합니다.
성능 손실없이 메모리를 줄일 수 있었던 핵심 포인트는 4-bit NormalFloat (NF4), Double Quantization과 Paged Optimizers을 사용했기 때문이었습니다. 이제 이 개념들이 무엇이고 QLoRA가 어느 정도의 성능을 달성했는지 구체적으로 살펴보겠습니다.
모델 구조
양자화
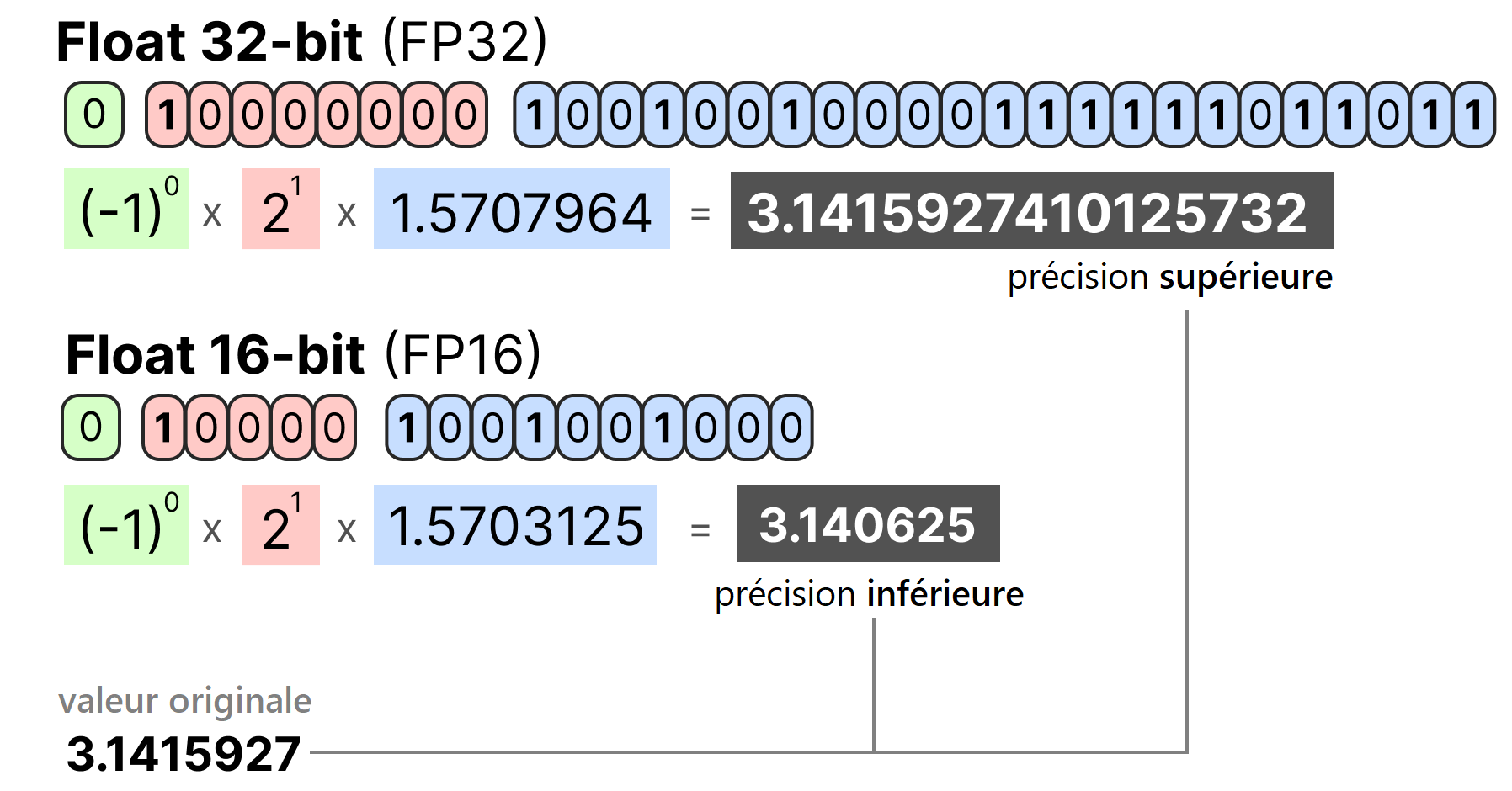
GPT-3 이후 LLM 학습 단계에서 FP16/BF16 + FP32를 섞어 쓰는 ‘mixed-precison‘을 사용하고, FP16/BF16 형식으로 weight를 저장해 배포하는 것이 사실상 표준이 되었습니다. 모델 파라미터 수가 수십억~수천억 개로 커지면서 32-bit weight를 그대로 GPU 메모리에 올리기에는 메모리 부담이 너무 커졌기 때문입니다.
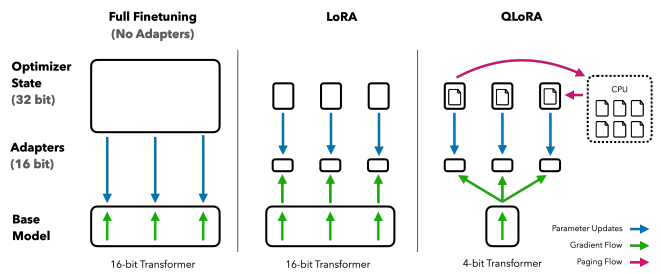
QLoRA는 여기에서 한 발 더 나아가서 모델 weight를 32-bit에서 4-bit로 8배 압축합니다. 학습 과정을 단계별로 정리해보면 아래와 같습니다.
| 단계 | 핵심 아이디어 |
|---|---|
| 1. 4-bit 양자화 | • NF4(NormalFloat-4): 정규 분포 weight에 정보이론적으로 최적화된 새로운 4-bit 자료형 • Double Quantization: 양자화 상수까지 한 번 더 양자화 → 약 3GB 추가 절감 |
| 2. 모델 freeze | 양자화된 $W$ 4-bit(FP4/NF4) 읽기 전용 |
| 3. LoRA | 각 linear layer에 저차원 행렬 $A(r × d)$, $B(d × r)$ 삽입, $\Delta$만 16-bit로 학습 |
| 4. Paged Optimizer | NVIDIA Unified Memory를 이용해 미니배치마다 튀는 메모리 스파이크 완화 → 단일 GPU 유지 |
결과적으로 QLoRA는 16bit full fine-tuning했을 때 평균 메모리가 780GB 이상 소요되던 것(LLaMA 65B 모델 기준)을 성능 손실없이 48GB 이하로 줄였습니다.
| 지표 (LLaMA 65B) | 16-bit FT | LoRA(r=64) | QLoRA |
|---|---|---|---|
| VRAM 필요량 | 780 GB | 350 GB | < 48 GB |
| 저장 크기 | 130 GB | 35 MB($\Delta$) | 35 MB($\Delta$) |
| 속도 오버헤드 | – | 0 (추론 전 $W+\Delta$ 합치기) | 0 |
모델 성능
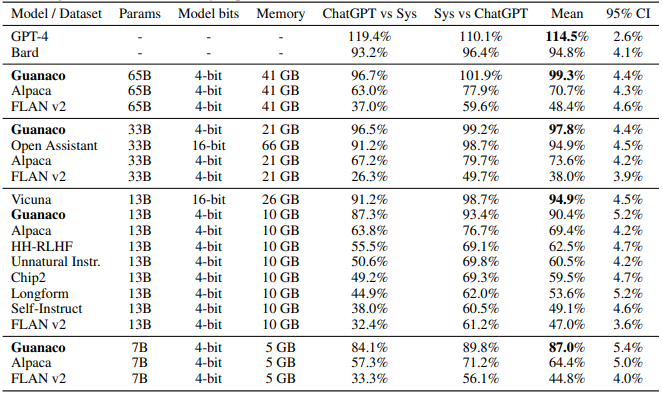
위 표는 Vicuna benchmark에서 모델별 평균 성능을 비교한 결과입니다. Guanaco 65B 모델은 단 하나의 GPU로 24시간 학습한 모델인데, 선행 모델들보다 더 뛰어난 성능을 보였습니다. Guanaco 33B 모델은 하나의 GPU로 12시간 학습한 모델로, 매우 적은 학습 시간으로도 ChatGPT(2023년 기준)에 버금가는 수준의 성능을 보였습니다.
Reference
- https://lbourdois.github.io/blog/Quantification/