[Paper Review] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
[Paper Review] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
보통 CNN 모델은 입력 이미지 사이즈가 고정되어 있어야 합니다. 이런 제약사항으로 인해, 임의의 사이즈 및 가로세로비를 갖는 이미지들에 대한 정확도가 감소할 수 있는데요. 본 논문에서는 이미지 사이즈에 관계없이, 고정된 길이의 representation을 생성하는 새로운 pooling 전략을 제안합니다.
저자들은 Spatial pyramid pooling 구조를 사용했을 때, CNN 모델의 구조와 관계없이 이미지 분류 모델의 성능이 향상됨을 확인했습니다. 기존 object detection 모델과 비교했을 때 SPPNet은 전체 이미지로부터 convolutional feature map을 한 번만 계산하기 때문에 테스트 시에 속도가 빠르고, 정확도도 향상되었습니다.
Introduction
- 기존 CNN 모델에 임의의 사이즈 및 가로세로비를 갖는 이미지를 입력하려면, crop하거나 warp 해야 함 → 정보 손실 및 이미지 변형 발생
- 기존 CNN 모델이 고정된 사이즈 및 가로세로비를 갖는 입력 이미지를 필요로 하는 것은 convolutional layer 때문이 아니라 fully connected layer 때문 (fully connected layer는 고정된 크기의 vector를 입력 값으로 받음)
- convolutional layer는 입력 이미지 크기에 관계없이, 이미지 상에서 어느 영역이 가장 활성화되었는지 보여주는 feature map을 생성할 수 있음. (feature maps involve not only the strength of the responses, but also their spatial positions.)

SPPNet의 작동 방식
- SPP layer를 마지막 convolutional layer 위에 쌓는 방식 (마지막 pooling layer를 SPP layer로 교체)
input layer임의의 사이즈 및 가로세로비를 갖는 이미지 입력 →convolutional layerfeature map 생성 →SPP layer고정된 길이의 output을 생성(information aggregation) →fully connected layer에 입력
SPPNet의 강점
- 입력 이미지의 크기 및 가로세로비에 관계없이 고정된 길이의 output을 생성할 수 있음. crop이나 warp이 필요하지 않음
- multi-level pooling을 사용하기 때문에 object의 변형에도 강건
- (입력 이미지 크기의 유연성 덕분에) 가변적 크기의 이미지에서 추출된 feature를 pool할 수 있기 때문에 모델 성능 향상. (다양한 크기의 object로부터 feature를 추출하기 때문에) 학습할 때부터 가변적 크기의 입력 이미지를 사용하기 때문에, scale-invariance를 향상시키고 over-fitting을 완화시킴
multi-size training method
- 여러 개의 모델이 파라미터를 서로 공유
- 각각의 epoch에서 특정 크기의 입력 이미지를 사용 → 다음 epoch에서는 다른 크기의 입력 이미지를 사용
- 하나의 고정된 사이즈의 입력 이미지를 사용하는 기존 방식과 동일하게 수렴하면서도, test acc가 향상됨
object detection 영역에서의 SPPNet
- R-CNN은 ~2K개의 후보 영역 각각에 대하여 convolutional feature map을 계산하기 때문에 계산량이 너무 많고, 시간이 오래 걸림 ↔ SPPNet은 전체 이미지에 대하여 convolutional feature map을 한 번만 계산
- feature map 위에서 detector를 작동시키는 것은 기존에도 사용되고 있는 방식이지만, SPP-net inherits the power of the deep CNN feature maps 그리고 window 크기의 유연성 덕분에 정확도와 효율성이 크게 상승함
DEEP NETWORKS WITH SPATIAL PYRAMID POOLING
The Spatial Pyramid Pooling Layer
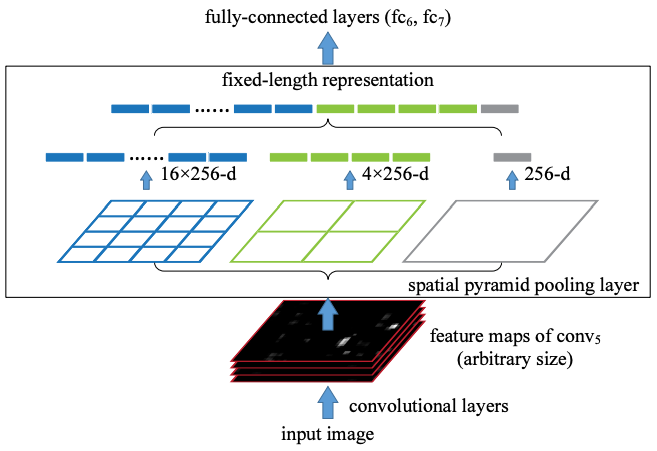
- local spatial bin에서 feature를 pool하기 때문에 위치 정보 보존 가능 → BoW보다 성능 향상
- spatial bin의 크기는 입력 이미지의 크기에 비례함 → 이미지 크기에 관계없이, bin 개수 고정
- SPP layer의 output은 입력 이미지 크기에 관계없이 $kM$ 차원의 벡터 ($k$는 마지막 conv layer의 filter 개수, $M$은 bin 개수)
- 전체 feature 영역에서 하나의 feature를 추출하는, 하나의 bin을 갖는 pyramid 층은 사실상 global pooling을 수행하는 것
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import torch
import torch.nn as nn
from torch.nn import init
import functools
from torch.autograd import Variable
import numpy as np
import torch.nn.functional as F
from spp_layer import spatial_pyramid_pool
class SPP_NET(nn.Module):
def __init__(self, opt, input_nc, ndf=64, gpu_ids=[]):
super(SPP_NET, self).__init__()
...
def forward(self,x):
x = self.conv1(x)
x = self.LReLU1(x)
x = self.conv2(x)
x = F.leaky_relu(self.BN1(x))
x = self.conv3(x)
x = F.leaky_relu(self.BN2(x))
x = self.conv4(x)
spp = spatial_pyramid_pool(x,1,[int(x.size(2)),int(x.size(3))],self.output_num)
fc1 = self.fc1(spp)
fc2 = self.fc2(fc1)
s = nn.Sigmoid()
output = s(fc2)
return output
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import math
def spatial_pyramid_pool(self,previous_conv, num_sample, previous_conv_size, out_pool_size):
for i in range(len(out_pool_size)):
# print(previous_conv_size)
h_wid = int(math.ceil(previous_conv_size[0] / out_pool_size[i]))
w_wid = int(math.ceil(previous_conv_size[1] / out_pool_size[i]))
h_pad = (h_wid*out_pool_size[i] - previous_conv_size[0] + 1)/2
w_pad = (w_wid*out_pool_size[i] - previous_conv_size[1] + 1)/2
maxpool = nn.MaxPool2d((h_wid, w_wid), stride=(h_wid, w_wid), padding=(h_pad, w_pad))
x = maxpool(previous_conv)
if(i == 0):
spp = x.view(num_sample,-1)
else:
spp = torch.cat((spp,x.view(num_sample,-1)), 1)
return
Training the Network
Single-size training
- fixed-size input (224×224) cropped from img.
Multi-size training
- two sizes input: 180×180(224x224를 resize), 224×224
- 180-network와 224-network는 파라미터를 공유하고, SPP layer의 output 길이는 동일
- 한 epoch에서 특정 사이즈로 학습 → 다음 epoch에서 다른 사이즈로 학습 (반복)
- The main purpose of our multi-size training is to simulate the varying input sizes while still leveraging the existing well-optimized fixed-size implementations.
SPP-NET FOR IMAGE CLASSIFICATION
Experiments on ImageNet 2012 Classification
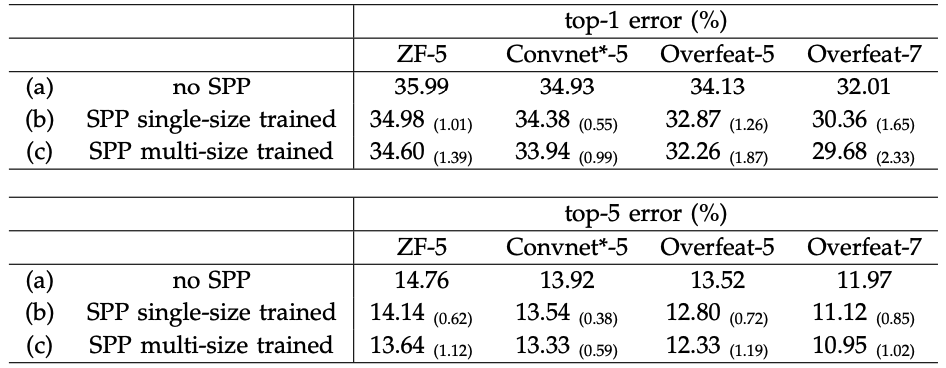
- 이미지 transform 및 하이퍼 파라미터 설정
- 입력 이미지들은 the smaller dimension이 256이 되도록 resize한 뒤, 전체 이미지의 중앙이나 코너에서 224x224 crop
- data augmentation은 horizontal flipping과 color altering 사용
- Fully connected layer 두 개에 Dropout 사용
- learning rate는 0.01에서 시작
- 모든 no-SPP baseline 모델들보다 error rate 감소했는데, 이는 단순히 파라미터가 증가했기 때문이 아니라, multi-level pooling is robust to the variance in object detormations and spatial layout 이기 때문에 얻은 성과임
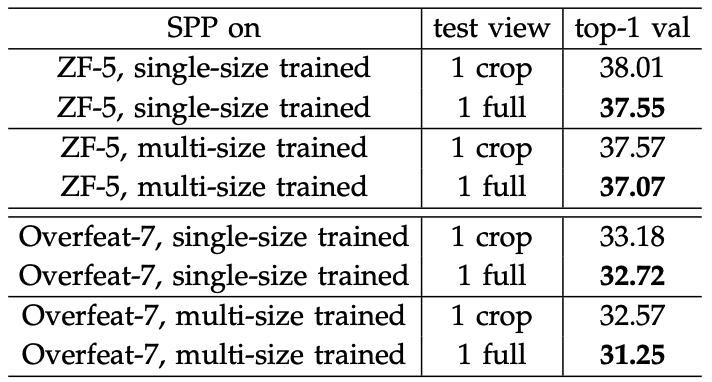
- 모든 모델에서 full 이미지를 사용했을 때 error rate가 낮은데, 이는 전체 정보를 유지하는 것이 중요함을 보여줌
- 정사각형 이미지로만 학습했는데도 직사각형 이미지에도 일반화 성능이 좋았음
This post is licensed under CC BY 4.0 by the author.