[Paper Review] StyleGAN
[Paper Review] StyleGAN
본 포스트에서는 NVIDIA에서 발표한 이미지 생성 모델 StyleGAN에 대해 알아보려고 합니다. StyleGAN은 이미지의 특징 제어 관점에서 높은 성능을 달성한 모델인데요. StyleGAN에 대해 알아보기 전에, StyleGAN의 토대가 된 모델인 ProGAN을 살펴보겠습니다. ProGAN 역시 NVIDIA에서 발표한 모델로, ProGAN에서 생성자만 바뀐 모델이 StyleGAN입니다.
1. Progressive Growing of GANs (2017)
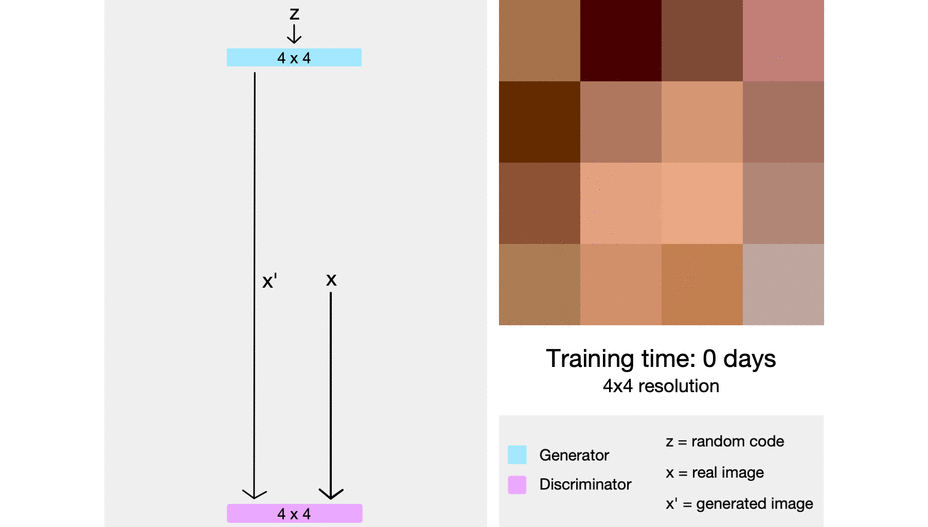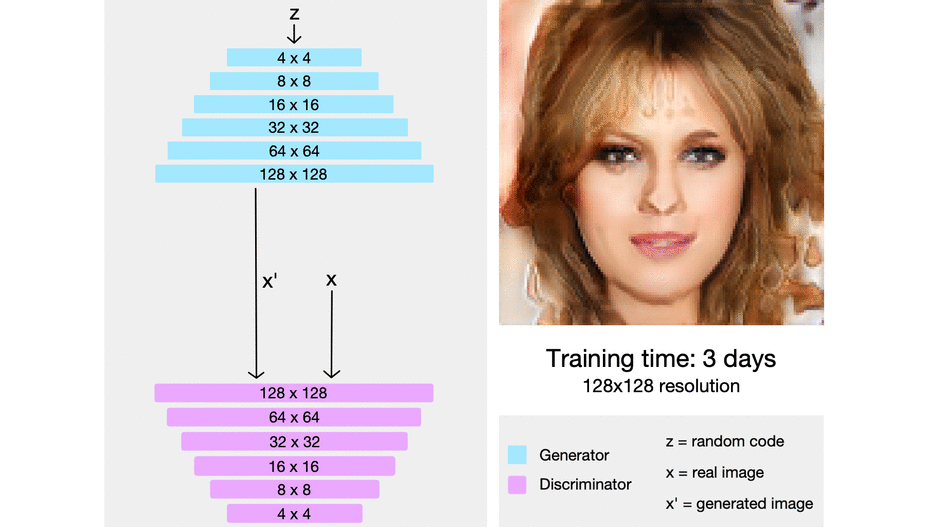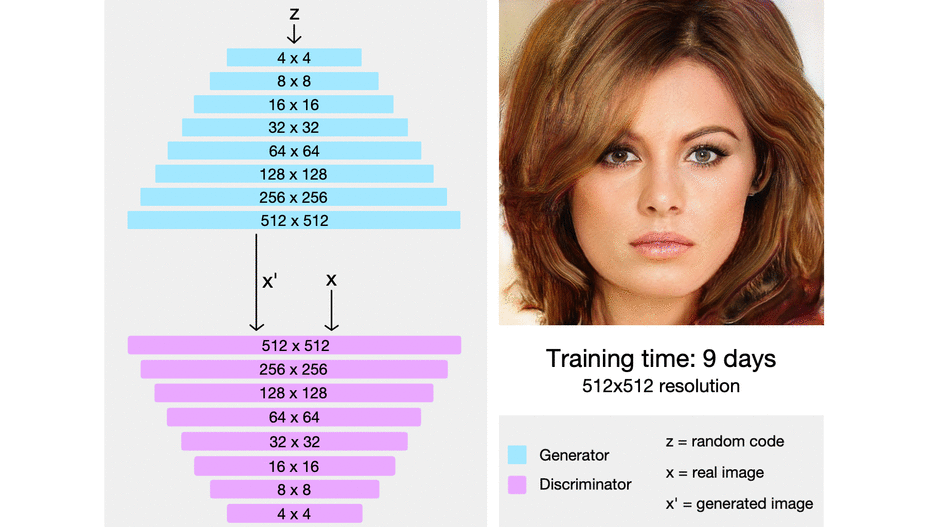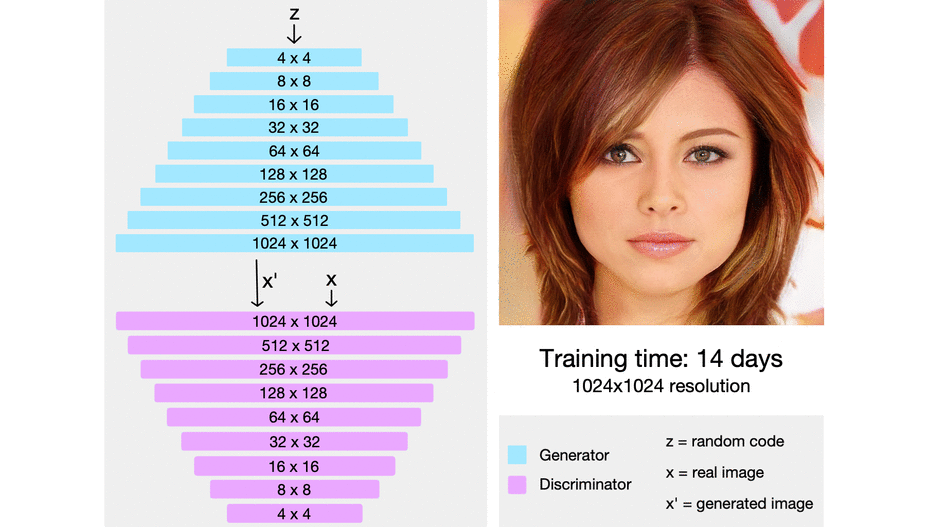
- official code
- 처음부터 복잡한 네트워크를 학습하는 것이 아니라, 저해상도에서 고해상도로 학습을 진행하는 과정에서 점진적으로 네트워크의 레이어를 붙여 나감
- 한계점
- 이미지의 특징들이 분리되지 않아 특징 제어가 어려움
2. StyleGAN (2018)
- official code
- Disentanglement 특성을 향상시켜 이미지의 특징 제어가 어려운 ProGAN의 한계점을 개선함
- Disentanglement: 생성된 이미지의 특정 attribute를 분리하여 조절할 수 있는 능력
- 생성 모델의 Disentanglement 성능이 낮다면, 얼굴 이미지에서 안경만 제거하고 싶거나 피부 색상만 변경하려고 할 때 의도하지 않은 attribute 변경이 발생할 수 있음
- 고해상도 얼굴 데이터셋(FFHQ)을 발표
- 생성 모델의 새로운 평가 지표 제안
모델 구조
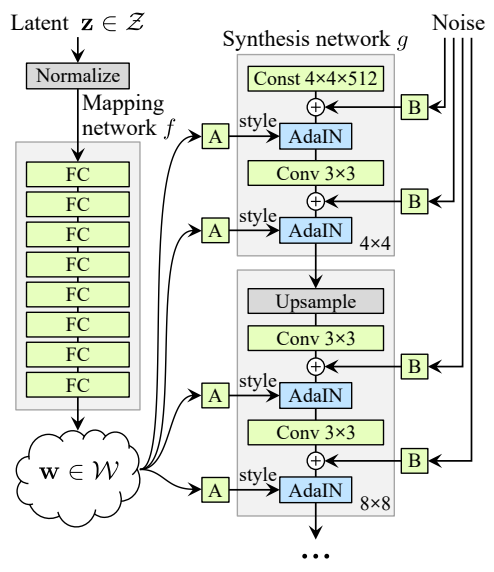 StyleGAN generator architecture
StyleGAN generator architectureMapping Network
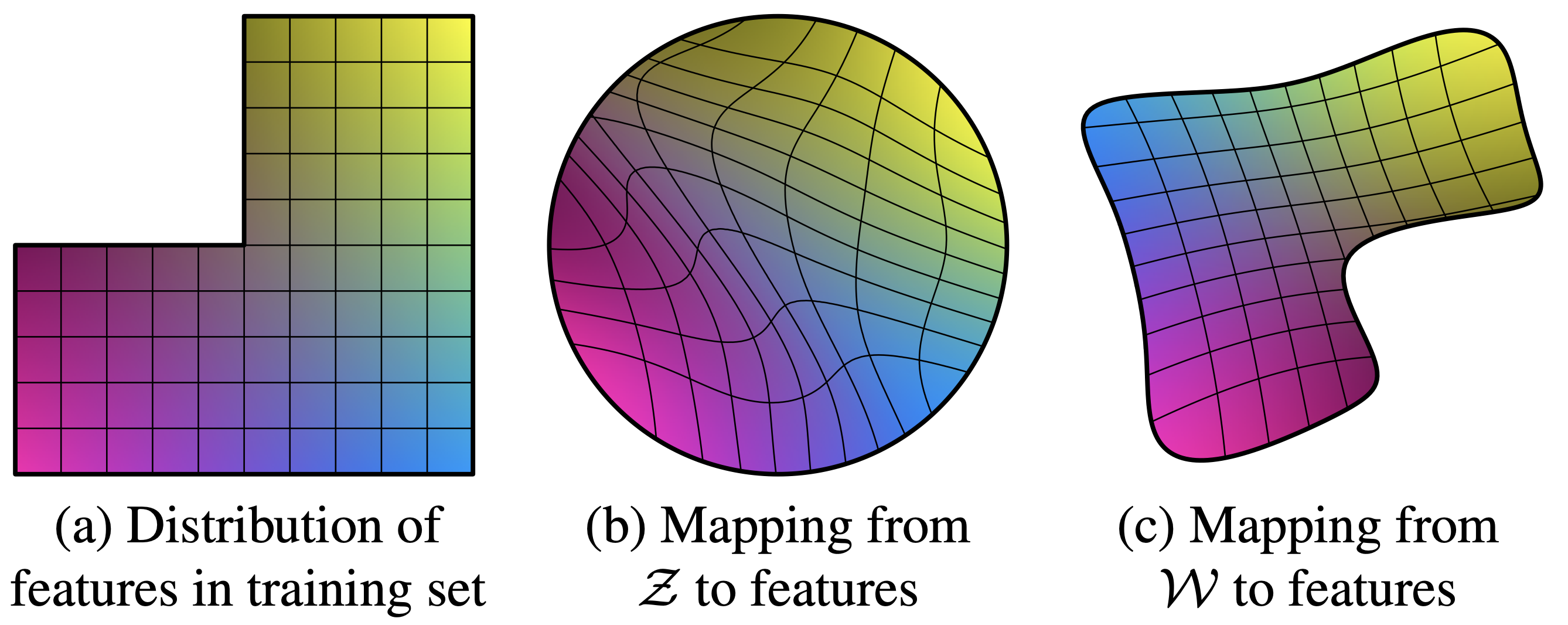
- 8개의 layer로 구성된 Mapping Network $f$를 사용해 512 차원의 latent vector $z$를 domain $\mathcal{Z}$에서 domain $\mathcal{W}$로 매핑
- (a)는 학습 데이터의 분포. 좌측 상단이 비어 있는 것은 특정 조합의 이미지(예를 들어, 머리가 긴 남성 이미지)가 존재하지 않음을 의미. 모델이 있을 법한 이미지를 생성하려면 이러한 비정상적인 조합을 생성하지 않아야 함.
- 학습 데이터에서 특정 조합이 누락되어 있기 때문에, input latent space $\mathcal{Z}$에서의 mapping은 이러한 누락된 조합을 반영하여 곡선으로 나타남. entanglement 발생을 피하기 어려움
- intermediate latent space $\mathcal{W}$에서 샘플링한 $w$ vector를 사용하면 특징들을 분리할 수 있음
Adaptive Instance Normalization (ADaIN)
- official code
- instance normalization
주어진 feature map의 각 pixel $x_i$에 대해 각 channel의 feature map을 정규화하는 방법. 아래 식에서 $\mu_X$는 feature map $X$의 평균, $\sigma_X$는 feature map $X$의 표준편차
\[\text{IN}(x_i)=\frac{x_i-\mu_X}{\sqrt{\sigma^2_X+\epsilon}}\]
- Adaptive Instance Normalization (ADaIN)
- 학습시킬 파라미터가 없다는 장점이 있음
- 입력 이미지의 통계적 특성을 style vector와 유사하게 만들어 style을 적용하는 것
- 먼저, 입력된 feature map의 평균과 분산을 각각 0과 1로 정규화.그 다음 해당 feature map의 평균을 style vector의 평균으로 조정하고, 입력 이미지의 표준편차를 style vector의 표준편차로 스케일링. 아래 식에서 $y_{s,i}$는 style vector의 표준편차이고, $y_{b,i}$는 style vector의 평균
ADaIN이 사용된 feed-forward 방식의 style transfer network
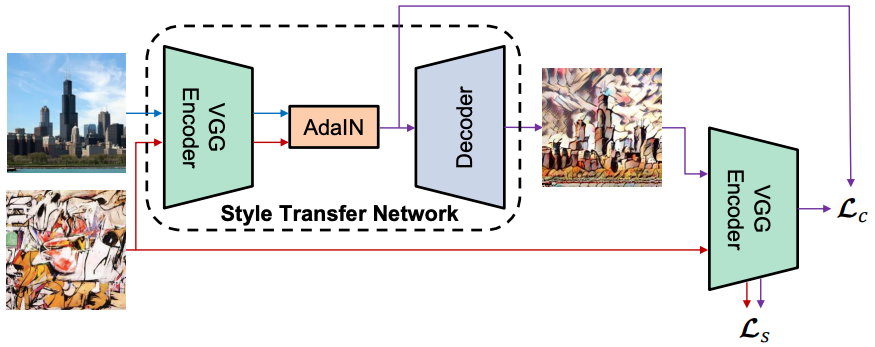
encoder(fixed VGG-19)가 이미지의 content와 style을 인코딩하고,ADaIN layer는 encoder의 output을 입력받아 feature space에서 style transfer를 수행함decoder는ADaIN layer의 output을 image space로 변환함- content loss $\mathcal{L}_c$와 style loss $\mathcal{L}_s$를 계산하기 위해 동일한
encoder사용
- 다양한 stochastic variation을 구현할 수 있도록 Noise를 함께 입력함 (확률적 다양성을 구현)
- Style-Mixing
3. StyleGAN2 (2019)
- official code
- StyleGAN의 한계점
- 물방울이 번진 것 같은 부자연스러운 부분이 자주 발생했는데, 이는 ADaIN 때문에 발생
- Normalization이 Feature map의 정보를 파괴
- 확률적 다양성을 구현하기 위해 도입된 Noise가 ADaIN 직전에 더해져 영향력이 비일관적
- 물방울이 번진 것 같은 부자연스러운 부분이 자주 발생했는데, 이는 ADaIN 때문에 발생
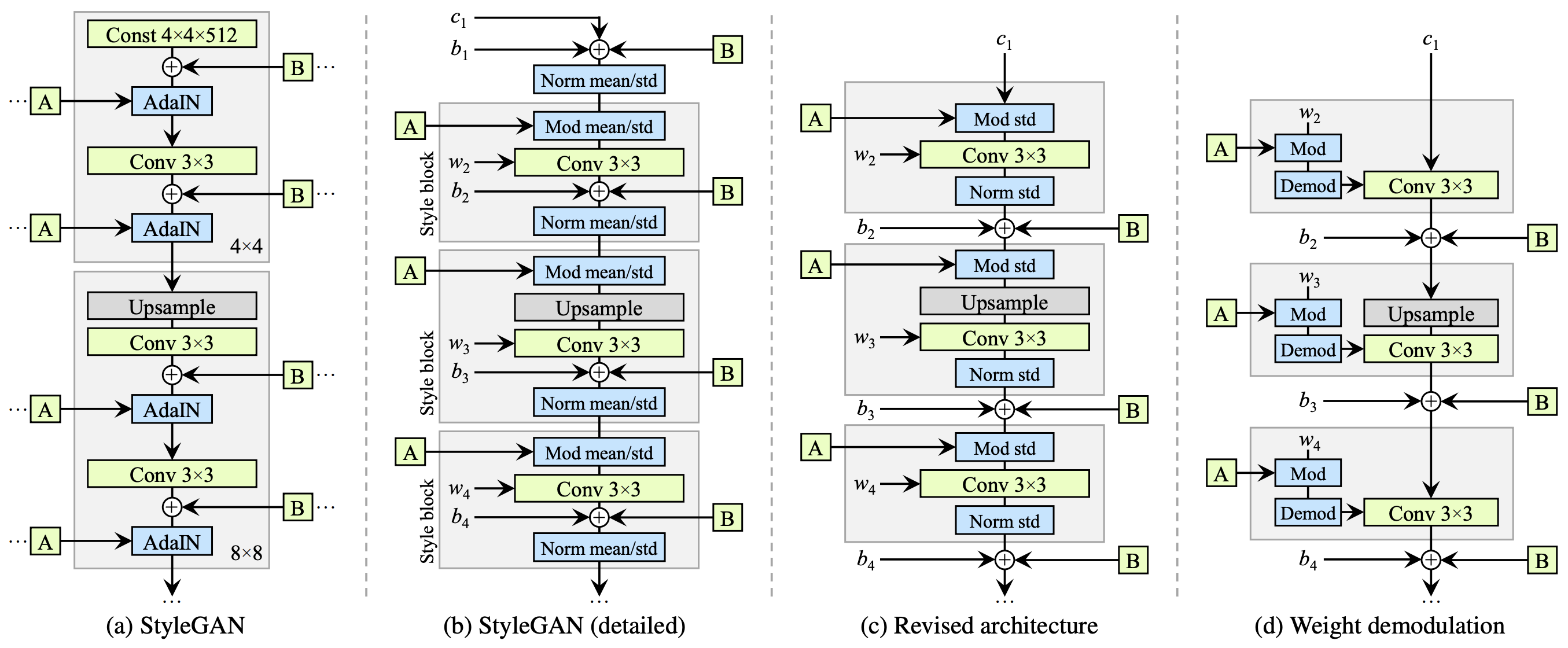
- 평균에 대한 Normalization 및 Modulation 제거
- standard deviation만 1로 만들어 줌 (원하는 style을 주입하는 단계, 위 그림 (c)에서 Norm std)
- standard deviation만 1로 만들어 준 다음에 Noise를 더해주도록 순서를 바꿈
- 약한 형태의 Normalization을 사용
- feature map을 직접 Normalization 하지 않음 (feature map의 각 채널들이 표준 정규분포를 따르도록 Normalization이 강제되지 않음)
- Convolution 가중치 $w$에 Modulation / Demodulation 적용 (d)
Reference
This post is licensed under CC BY 4.0 by the author.