[Paper Review] Generating Diverse High-Fidelity Images with VQ-VAE-2
VQ-VAE 2는 VQ-VAE의 한계점을 개선하기 위해 나온 후속 모델입니다. 저자들은 이전 논문에서 아래와 같이 언급했는데요.
Training the prior and the VQ-VAE jointly, which could strengthen our results, is left as future research.
여기서 향후 과제로 남겨둔, VQ-VAE와 prior를 함께 학습하는 모델이 바로 VQ-VAE 2입니다. 또한 prior $p(z)$를 학습하는 구조를 계층적으로 변경하여 이미지 생성 품질을 한 층 끌어올렸습니다. VQ-VAE 2에 대해 자세히 알아보기 전에 VQ-VAE와의 차이점을 간단히 정리해보면 아래와 같습니다.
| VQ-VAE (2017) | VQ-VAE-2 (2019) | |
|---|---|---|
| Latent Layers | Single latent layer | Multi-scale hierarchical latent layers |
| prior $p(z)$ | single-layer autoregressive prior VQ-VAE 학습이 끝난 뒤 따로 학습 | hierarchical autoregressive priors for each latent level VQ-VAE 2와 함께 학습 |
1. 모델 구조
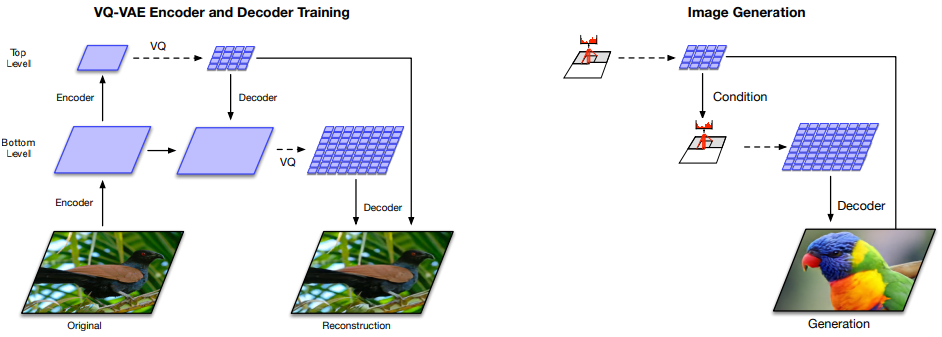
VQ-VAE 2는 이미지를 pixel space가 아니라 discrete latent space로 매핑한다는 점에서는 VQ-VAE와 동일합니다. 이러한 매핑 방식은 representation을 원본 이미지보다 30배 이상 작게 압축하지만, 이를 입력받은 Decoder는 이미지를 거의 왜곡하지 않고 reconsturciton할 수 있습니다.
VQ-VAE Encoder and Decoder Training
좌측 그림은 VQ-VAE 2를 학습하는 과정을 보여줍니다. 256 X 256 사이즈의 Original 이미지가 Encoder에 입력되면, 먼저 Top Level에서 continuous latent map을 생성하고 VQ를 수행해 discrete latent code로 변환합니다. 그리고 이 discrete latent code에 대응하는 vector를 codebook에서 찾아서 continuous latent map으로 복원하는 embedding 과정을 거칩니다.
그 다음, Bottom Level에서는 Top Level의 discrete latent code를 조건으로 사용해서 continuous latent map을 생성하고 동일하게 VQ, embedding을 수행합니다. Bottom Level은 질감 같은 local 정보를, Top Level은 물체의 위치나 전체적인 모양 같은 global 정보를 수집합니다. 이렇게 단계별로 latent map을 만들면, 그 단계에서 수집할 수 있는 정보에만 집중할 수 있고, 그 정보들이 상호 보완적으로 작용해서 reconstruction error를 줄일 수 있습니다. 결과적으로 Decoder는 서로 다른 크기(64 X 64, 32 X 32)의 latent map를 활용해 이미지를 reconstruct합니다.
Image Generation
우측 그림은 학습된 모델로 이미지를 생성하는 과정을 보여줍니다. (Conditional generation일 경우) Top Level의 PixelCNN prior는 class label을 조건으로 sampling하고, 다음으로 Bottom Level의 PixelCNN prior는 class label과 Top Level latent code를 조건으로 sampling합니다. 최종적으로 Bottom Level의 PixelCNN prior으로부터 sampling해서 discrete latent code를 얻고, Decoder는 code를 embedding한 결과를 입력으로 받아 이미지를 생성합니다.
- $z_t \sim p(z_t)$
- $z_b \sim p(z_b \mid z_t)$
- $\hat{x} = \text{Decoder}(z_b)$
2. 모델 성능
 Class-conditional Samples (128x128) from a VQ-VAE
Class-conditional Samples (128x128) from a VQ-VAE
 Class-conditional samples (256x256) from a two-level VQ-VAE 2
Class-conditional samples (256x256) from a two-level VQ-VAE 2
위는 VQ-VAE의 이미지 생성 결과로, 컬럼 별로 각각 여우, 회색 고래, 갈색 곰, 나비를 생성한 것입니다. 아래는 VQ-VAE 2의 이미지 생성 결과인데요. 선행 연구인 VQ-VAE와 비교했을 때 물체와 배경이 잘 분리되어 있고, 선명한 고해상도의 이미지를 생성한 것을 확인할 수 있습니다.