[Paper Review] VQ-VAE: Vector Quantised-Variational AutoEncoder
VQ-VAE는 VAE와 discrete latent representation을 결합한 모델입니다. continuous representation을 학습하는 VAE 모델과 비슷한 성능을 보이면서 discrete distribution의 유연성도 가지고 있는 모델인데요. VQ-VAE에 대해 자세히 알아 보기에 앞서, VAE와의 차이점을 정리해보면 다음과 같습니다.
| VQ-VAE | VAE | |
|---|---|---|
| encoder output | discrete representation | continuous representation |
| prior $p(z)$ | 학습 | 고정 (가우시안 분포로 가정) |
VQ-VAE와 VAE의 가장 큰 차이점은 continuous representation이 아니라 discrete representation을 학습한다는 점에 있습니다. 논문에 따르면, continuous representation보다 discrete representation이 언어, 음성, 이미지 등 서로 다른 유형이나 형식의 데이터(modality)에서 자연스러운 표현 방법일 수 있다고 합니다. 언어는 본질적으로 불연속적이고, 음성도 기호들의 sequence로 표현되며, 이미지는 언어로 간결하게 설명할 수 있기 때문입니다.
또한 VQ-VAE는 discrete latent representation과 autoregressive prior를 결합해서 discrete하고 유용한 latent variable을 학습함으로써 고품질의 데이터를 생성합니다. autoregressive prior는 모델이 latent variable $z$를 생성할 때 이전의 변수를 기반으로 다음 변수를 생성하는 방식입니다. 이는 latent variable $z$들이 sequence 형태로 존재하며, 각 variable은 이전 variable에 의존하여 결정되는 분포를 따른다는 것을 의미합니다.
- [이미지] 이미지의 각 픽셀이 이전 픽셀들에 의존하는 방식으로 이미지를 생성합니다. 예를 들어, PixelCNN은 $x_i$가 하나의 픽셀일 때, 이미지 $x$에 대한 픽셀들의 joint distribution $p(x)$는 conditional distribution의 곱으로 모델링합니다.
![]()
- [오디오] 음성 신호의 각 샘플이 이전 샘플에 의존하여 생성됩니다. 예를 들어, WaveNet과 같은 모델이 사용됩니다.
- [텍스트] 문장의 각 단어가 이전 단어들에 의존하여 생성됩니다.
1. 모델 구조
1.1 Discrete Latent variables
latent embedding space $e \in R^{K \times D}$
- $K$는 discrete latent space의 크기 $e_i \in R^D, i \in 1, 2, … K$
- $D$는 각각의 latent embedding vector $e_i$의 차원 크기
1.2 Learning
1.2.1 Forward Computation
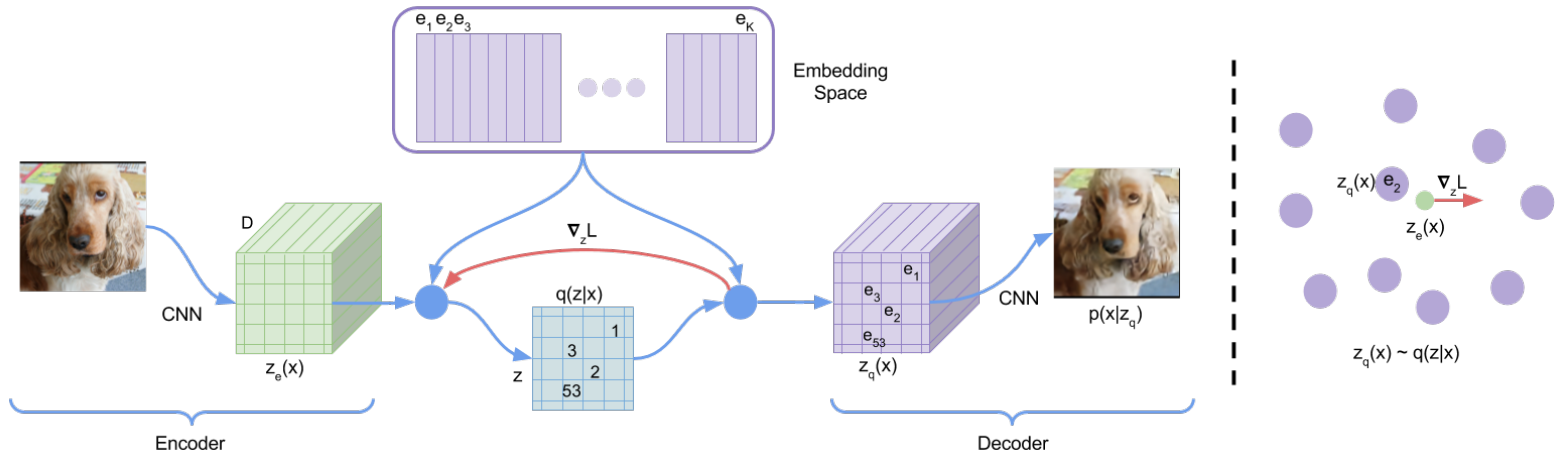
step 1encoder는 input 이미지 $x$를 입력받아서 continuous representation $z_e(x)$를 출력합니다.step 2continuous representation $z_e(x)$는 Vector Quantization를 통해 embedding space $e$에서 가장 가까운 embedding vector $z_q(x)$로 매핑됩니다. $z_q(x)$가 사전에 정의된 codebook vector 중 가장 가까운 vector로 변환되는 것입니다.
step 3decoder는 $z_q(x)$를 입력받아서 input 이미지 $x$를 복원합니다.
1.2.2 Backward Computation
step 1loss function $L$의 gradient $\bigtriangledown_zL$는 decoder input $z_q(x)$에 대해 계산됩니다.step 2gradient $\bigtriangledown_zL$는 그대로 복사되어 encoder output $z_e(x)$에 전달됩니다. Vector Quantization 과정이 불연속적이어서 직접적인 gradient 계산이 불가능하기 때문에 이러한 방식을 사용합니다. encoder의 output representation과 decoder의 input이 동일한 $D$ 차원의 space를 공유하고 있기 때문에, gradients는 reconstruction error를 낮추기 위해 encoder가 output representation를 어떻게 변화시켜야 하는지에 대한 유용한 정보를 포함하고 있습니다. 즉, encoder는 gradient 정보를 사용하여 input 이미지를 더 잘 표현할 수 있도록 학습합니다.
1.2.3 loss function
\[L = \log p(x | z_q(x)) + \| \text{sg}[z_e(x)] - e \|^2_2 + \beta \| z_e(x) - \text{sg}[e] \|^2_2\]- 첫번째 항은 reconstruction error
- 두번째 항은 embedding vector $e_i$를 encoder output $z_e(x)$로 이동시키기 위한 $l_2$ error로, code book을 업데이트하는 데에만 사용됩니다.
- 세번째 항은 commitment loss
- decoder는 첫번째 항에서, encoder는 첫번째 항과 세번째 항에서, embedding은 두번째 항에서 최적화됩니다.