[Paper Review] FaceNet: A Unified Embedding for Face Recognition and Clustering
이번 포스트에서는 Deep metric learning 모델 중 하나인 FaceNet(2015)에 대해 알아보겠습니다. Deep metric learning은 얼굴 인식, 화자 인식, 이미지 검색 등 여러 task에서 사용되고 있는 방식인데요. 모델 구조는 다양하지만, neural network를 사용해 이미지나 음성 데이터의 embedding vector를 학습하고, 샘플들 간의 embedding 거리를 계산하여 유사성과 비유사성을 학습한다는 점은 동일합니다. 이전 포스트에서 살펴본 Prototypical Networks도 Deep metric learning의 일종입니다.
FaceNet은 구글에서 2015년에 발표한 논문으로, 얼굴 인식, 얼굴 인증, 얼굴 군집화 등 다양한 얼굴 관련 작업을 하나의 embedding 공간에서 처리할 수 있게 한 모델입니다. 기존에는 얼굴 인식을 위해 CNN으로 feature를 뽑은 뒤 SVM이나 PCA 같은 후처리 기법을 쓰는 방식이 주류였는데, FaceNet은 End-to-End로 얼굴 embedding을 학습하고 이 embedding을 바로 사용해 모든 작업을 해결할 수 있다는 점에서 큰 혁신을 가져왔습니다.
1. 모델 구조

FaceNet은 당시 구글에서 개발한 GoogLeNet(Inception) 기반 CNN 모델을 사용해 이미지의 embedding vector를 추출했습니다. 그리고 embedding vector에 L2 정규화를 거쳐 모든 embedding vector가 unit hypersphere 위에 위치하도록 했습니다. 이렇게 하면 vector 크기가 일정하므로 순수하게 거리 기반 유사도 계산이 가능해지고, 검색 속도 또한 빠르다는 장점이 있습니다.
2. 핵심 아이디어: Triplet Loss
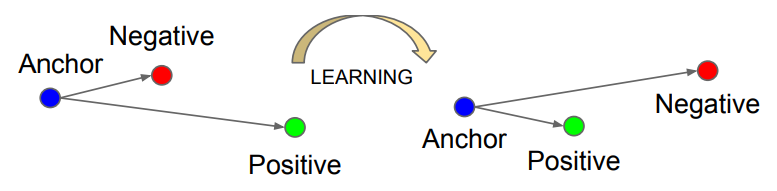
FaceNet이 유명해진 이유 중 하나는 바로 Triplet Loss라는 손실 함수를 제안했기 때문입니다.
- 얼굴 이미지를 neural network를 통해 embedding vector로 변환
- 같은 사람의 얼굴끼리는 임베딩 거리를 가깝게
- 다른 사람의 얼굴끼리는 임베딩 거리를 멀리 학습
이를 수식으로 표현하면 아래와 같습니다.
\[||f(x^a)−f(x^p)||_2^2+\alpha<||f(x^a)−f(x^n)||_2^2\]$x^a$: Anchor 이미지 (기준)
- $x^p$: Positive 이미지 (Anchor와 같은 사람)
- $x^n$ : Negative 이미지 (Anchor와 다른 사람)
- $f(\cdot)$: embedding vector로 매핑하는 neural network
- $\alpha$: margin 값
즉, 같은 사람의 얼굴끼리는 가깝게, 다른 사람의 얼굴과는 margin 이상 차이가 나도록 학습하는 것이 목표입니다.
Hard Negative Mining
Triplet Loss 학습에서 가장 중요한 건 어떤 triplet을 선택하느냐입니다.
- Easy Triplet: 이미 anchor-positive 거리가 작고, anchor-negative 거리가 큰 경우 → 학습에 도움 안 됨
- Hard Triplet: anchor-negative 거리가 anchor-positive보다 작은 경우 → 학습에 도움 되지만 너무 어려우면 수렴 방해
FaceNet은 Mini-batch 내부에서 negative 샘플 중 가장 anchor에 가까운 것을 뽑아 semi-hard negative mining을 수행합니다.
\[||f(x^a)−f(x^p)||<||f(x^a)−f(x^n)|| < ||f(x^a)−f(x^p)||+\alpha\]이러한 negative 샘플을 선택해 학습 효율을 높이고, 수렴 속도도 안정화시켰습니다.