[Paper Review] A ConvNet for the 2020s
이번 포스트에서 자주 등장하는 모델과 용어에 대한 설명은 아래 포스트를 참고해 주세요!
Introduction
2012년 AlexNet이 computer vision의 새 시대를 연 뒤로, 지난 10년간 vision recognition은 feature engineering에서 architecture design으로, 특히 ConvNet을 design하는 방향으로 발전해 왔습니다. ConvNet이 사용하는 sliding window 방식은 이미지 처리에 매우 중요한 역할을 하고, 특히 해상도가 높은 이미지를 처리할 때 잘 작동하는데요. 그 덕분에 ConvNet은 다양한 vision task에 잘 적용될 수 있도록 도와주는 inductive bias를 내재적으로 갖추게 되었습니다. 또한, feature map 위를 sliding 할 때 겹치는 영역에 대해 연산을 공유하기 때문에 효율적이라는 장점도 있습니다.
비슷한 시기에 NLP 영역에서는 Transformer가 RNN을 밀어내고 새로운 표준 모델로 떠올랐습니다. Vision Transformer는 Transformer를 vision 분야에 적용한 대표적인 모델인데요. 입력 이미지를 일련의 패치로 쪼개는 과정을 제외하고는 기존 Transformer의 구조를 최대한 그대로 유지했습니다. Vision Transformer는 Transformer 구조를 vision 분야에 적용할 수 있다는 잠재력을 보여주기에 충분했지만, ConvNet보다 inductive bias가 부족해서 대형 모델로 대규모 데이터셋을 학습하지 못하면 ResNet보다 낮은 성능을 보였습니다. 또한, global self-attention을 사용하기 때문에 입력 이미지 사이즈의 제곱에 비례하여 연산 복잡도가 증가한다는 문제점도 가지고 있습니다.
그래서 Vision Transformer 이후에 등장한 Swin Transformer는 Transformer가 ConvNet과 유사하게 작동할 수 있도록 hybrid 방식을 사용했습니다. Swin Transformer의 성공은 convolution의 중요성을 다시 한 번 상기시켜 주었는데요. 이러한 배경으로, 본 논문에서는 ResNet50과 Swin Transformer로 대표되는 ConvNet과 Transformer 모델의 차이를 살펴보고, confounding variable을 찾아봅니다. 이를 위해 저자들은 ResNet50에서 Swin Transformer로 모델을 조금씩 변형해 나가면서 ConvNet만으로 달성할 수 있는 성능의 한계가 어디까지인지, 모델 구조를 바꿀 때마다 성능은 어떻게 달라지는지 확인합니다. 이 때, attention 기반 구조는 전혀 사용하지 않았습니다.
Modernizing a ConvNet: a Roadmap
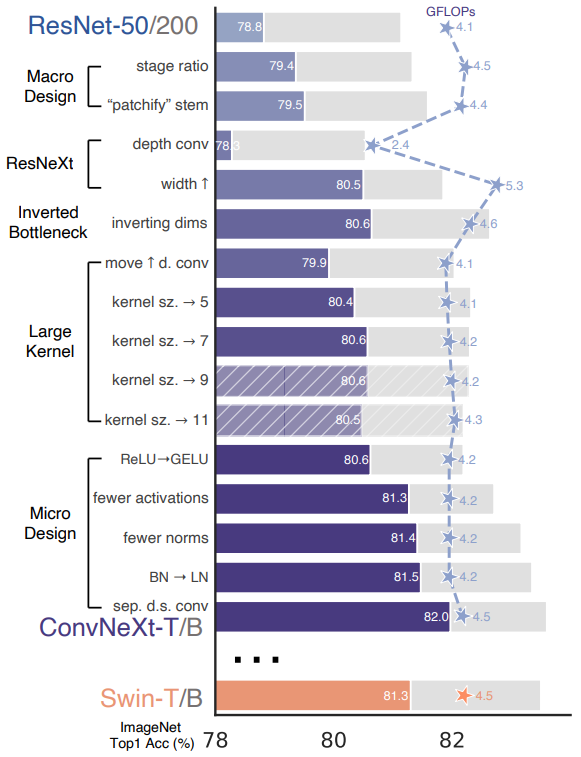
1. Training Techniques
모델 구조를 디자인하는 것과는 별개로, 학습 과정도 모델 성능에 큰 영향을 줍니다. 그래서 모델 구조를 바꾸기에 앞서, standard ResNet50에 아래와 같은 학습 방법을 적용해서 accuracy를 76.1%에서 78.8%로 향상시켰습니다.
- epoch 수를 90에서 300으로 증가
- AdamW optimizer 사용
- data augmentation 기법 적용
- Mixup
- Cutmix
- RandAugment
- Random Erasing
- regularization 기법 적용
- Stochastic Depth
- Label Smoothing
2. Macro Design
Changing stage compute ratio
각 stage의 block 개수를 (3, 4, 6, 3)에서 (3, 3, 9, 3)으로 변경하여 accuracy를 78.8%에서 79.4%로 향상시켰습니다.
Changing stem to “Patchify”
stem cell은 네트워크 시작 단계에서 입력 이미지를 어떻게 처리할 것인지를 의미합니다. Vision Transformer와 Swin Transformer는 입력 이미지를 패치로 쪼개는 과정(Patchfy)을 거치는데요. 이는 kernel 사이즈와 stride를 동일하게 설정한 non-overlapping convolution 연산으로 구현할 수 있습니다. standard ResNet의 7X7 conv layer & stride 2를 4X4 conv layer & stride 4로 변경했을 때 accuracy는 79.4%에서 79.5%로 다소 상승했습니다.
3. ResNeXt-ify
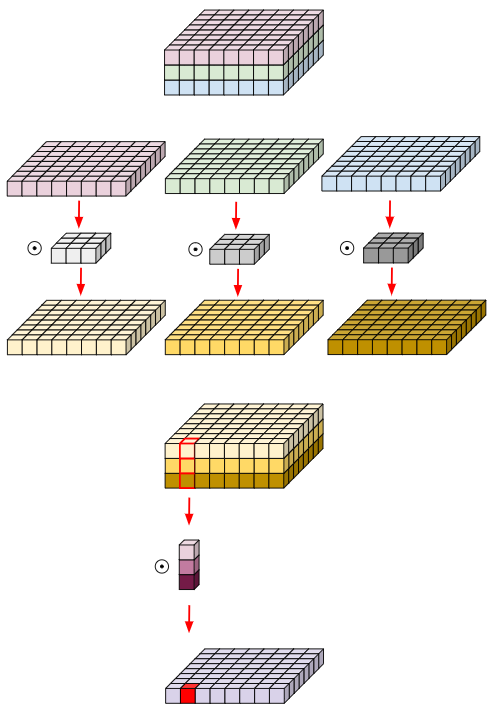
depthwise convolution을 사용하여 ResNeXt의 핵심 구조인 grouped convolution을 적용한 단계입니다. depthwise convolution은 group 개수와 channel 개수가 동일한 grouped convolution이라고 볼 수 있습니다. depthwise conv와 1X1 conv를 함께 사용하면 channel 간의 상관관계와 이미지 내 지역적인 상관관계를 분리하여 학습할 수 있으며, 이는 self-attention의 가중합 연산과 유사합니다. self-attention이 query와 key의 유사도를 가중치로 사용하여 value의 가중합을 구하는 것처럼, depthwise convolution은 channel별 convolution 연산을 거친 feature map의 가중합을 구하기 때문입니다. 채널 개수를 64개에서 96개로 늘리고 depthwise convolution을 사용했더니 accuracy가 79.5%에서 80.5%로 상승했습니다. 하지만 FLOPs도 5.3G로 증가했습니다.
4. Inverted Bottleneck
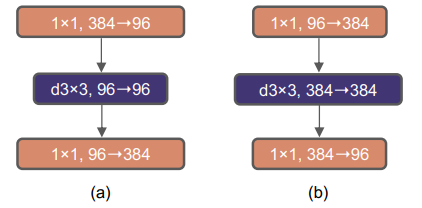
모든 Transformer 모델의 중요한 특징 중 하나는 MLP block의 hidden dimension이 입력 dimension보다 더 큰 inverted bottleneck을 사용했다는 점입니다. 위 그림에서 (a)는 ResNeXt의 bottleneck block이고, (b)는 (a)를 inverted bottleneck 구조로 변경한 것입니다. inverted bottleneck으로 구조를 변경했을 때 accuracy 변화는 80.5%에서 80.6%로 적은 성능 향상을 보였지만, FLOPs가 5.3G에서 4.6G로 감소했습니다.
5. Large Kernel Sizes
Moving up depthwise conv layer
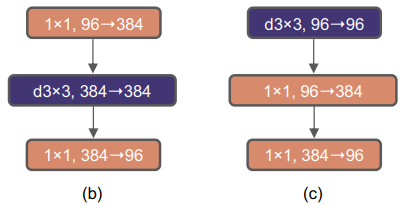
Kernel 사이즈를 키우기 위해 먼저 depthwise conv layer의 순서를 앞으로 이동했습니다. Transformer에서 MSA(multi-head self-attention) 구조도 MLP layer보다 앞에 위치하는데요. 이런 순서를 사용하면 상대적으로 복잡하고 비효율적인 구조인 MSA, large-kernel conv가 보다 적은 수의 channel을 처리하고, 1X1 conv layer는 많은 수의 channel을 처리하게 됩니다. 그 결과 accuracy는 80.6%에서 79.9%로 다소 감소했지만, FLOPs 역시 4.1G로 감소했습니다.
Increasing the kernel size
Kernel 사이즈를 3X3에서 7X7로 증가시켰더니 accuracy가 79.9%에서 80.6%로 상승했습니다. FLOPs는 거의 비슷하게 유지되었습니다.
6. Micro Design
Replacing ReLU with GELU
ReLU 대신 BERT, GPT-2와 Vision Transformer에서 사용한 activation function인 GELU를 사용했을 때는 성능 변화가 없었습니다.
Fewer activation function
Transformer는 MLP block에 위치한 하나의 activation function만 사용합니다. 이를 적용하기 위해 두 개의 1X1 conv layer 사이에 하나만 남겨두고 그 외에 모든 GELU activation function은 제거했습니다. 그 결과 accuracy가 80.6%에서 81.3%로 상승했습니다.
Fewer normalization layers
Transformer는 보통 적은 수의 normalization layer를 사용합니다. 그래서 1X1 conv layer 전에 하나의 BatchNorm layer만 남겨두고 나머지 두 개의 BatchNorm layer는 제거했습니다. 그 결과 accuracy 변화는 81.3%에서 81.4%로 적은 성능 향상을 보였지만 이 단계에서부터 SWIN Transformer를 앞지르기 시작했습니다.
Substituting BN with LN
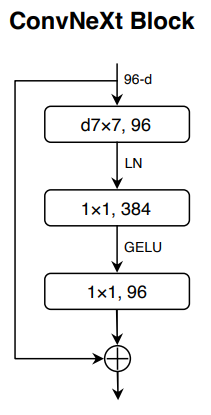
BatchNorm을 LayerNorm으로 변경했을 때 accuracy는 81.4%에서 81.5%로 다소 상승했습니다. 위 그림은 지금까지 적용한 사항들을 보여줍니다.
Separate downsampling layers
2X2 conv layer들을 stride 2로 사용하여 downsampling을 수행하도록 했을 때 accuracy가 81.5%에서 82%로 상승했습니다.