[Paper Review] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Introduction
Transformer가 NLP 분야의 새로운 표준으로 떠오르면서, Transformer를 vision 분야에도 적용하려는 다수의 연구가 진행되었습니다. 하지만 전체적인 CNN 구조를 유지한 모델이 많았는데요. 본 논문에서 제안하는 Vision Transformer는 기존 Transformer의 구조를 최대한 바꾸지 않고 높은 image classification 성능을 달성했습니다. 하지만 ImageNet과 같은 mid-sized dataset에 대해서는 ResNet보다 낮은 성능을 보였는데요. Transformer는 CNN 고유의 inductive bias가 부족하기 때문에 데이터 양이 충분하지 않으면 일반화 성능이 떨어진다고 합니다. Transformer와 inductive bias에 대한 자세한 설명은 아래 포스트를 참고해 주세요!
Related Work
가장 간단히 self-attention을 이미지에 적용할 수 있는 방법으로는 이미지 내에서 각각의 픽셀과 다른 모든 픽셀들의 attention 가중치를 구하는 방법을 생각해볼 수 있습니다. 이 방법은 계산 비용이 너무 많이 들어서 현실적인 크기의 입력 이미지에 적용하기가 어렵습니다. 그래서 approximation 방법들이 제안되었는데요. 각각의 픽셀 주변의 이웃 픽셀들과만 self-attention을 적용하는 방법 등이 있습니다. 하지만 이 방법들도 복잡한 엔지니어링이 요구된다는 제약이 존재합니다.
또다른 관련 연구로는 image GPT(iGPT)가 있는데요. 이미지 해상도와 color space를 축소한 다음 이미지 픽셀에 Transformer를 적용한 모델로, unsupervised 방식으로 학습합니다. (Vision Transformer는 supervised 방식으로 학습)
Method
Vision Transformer
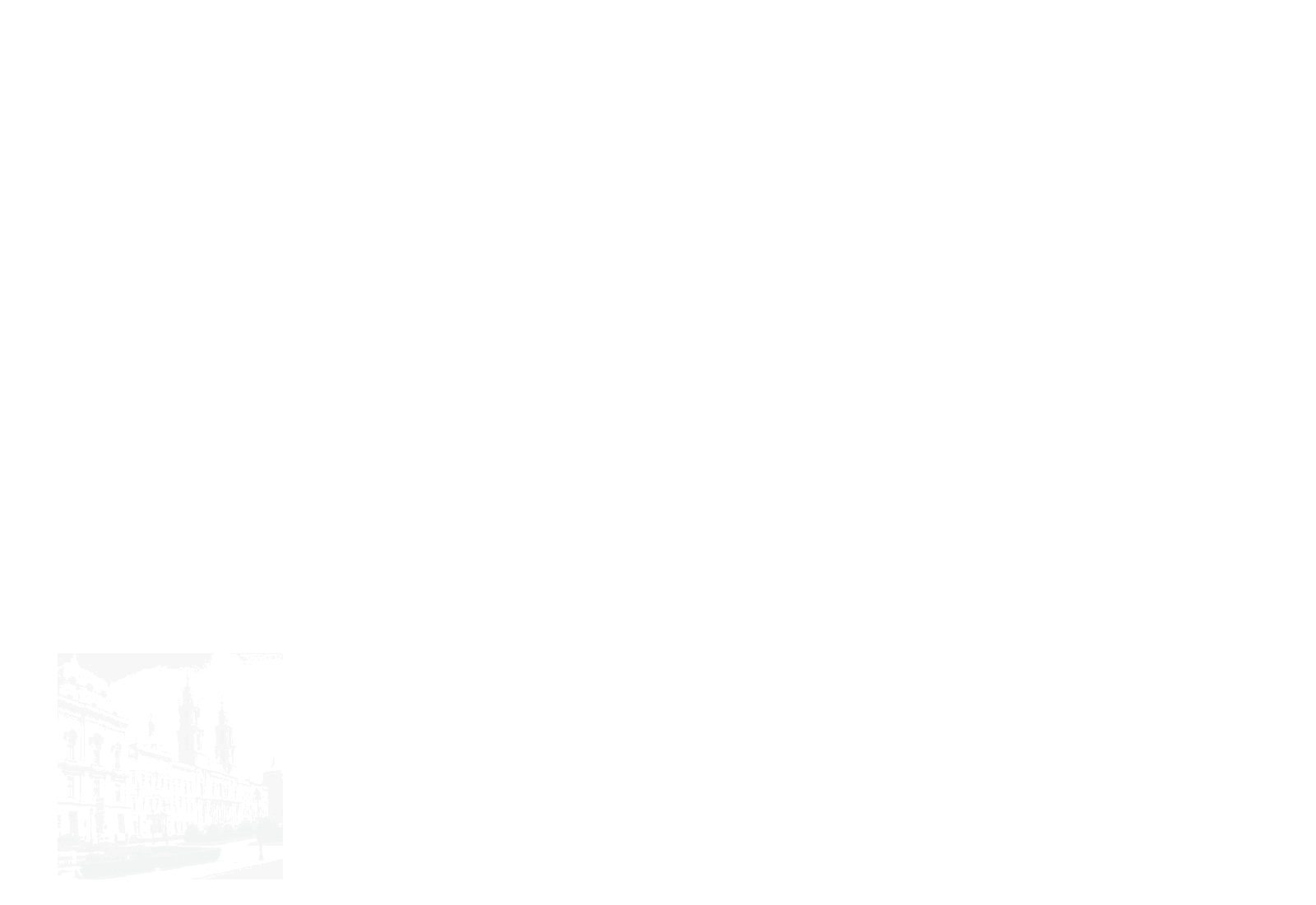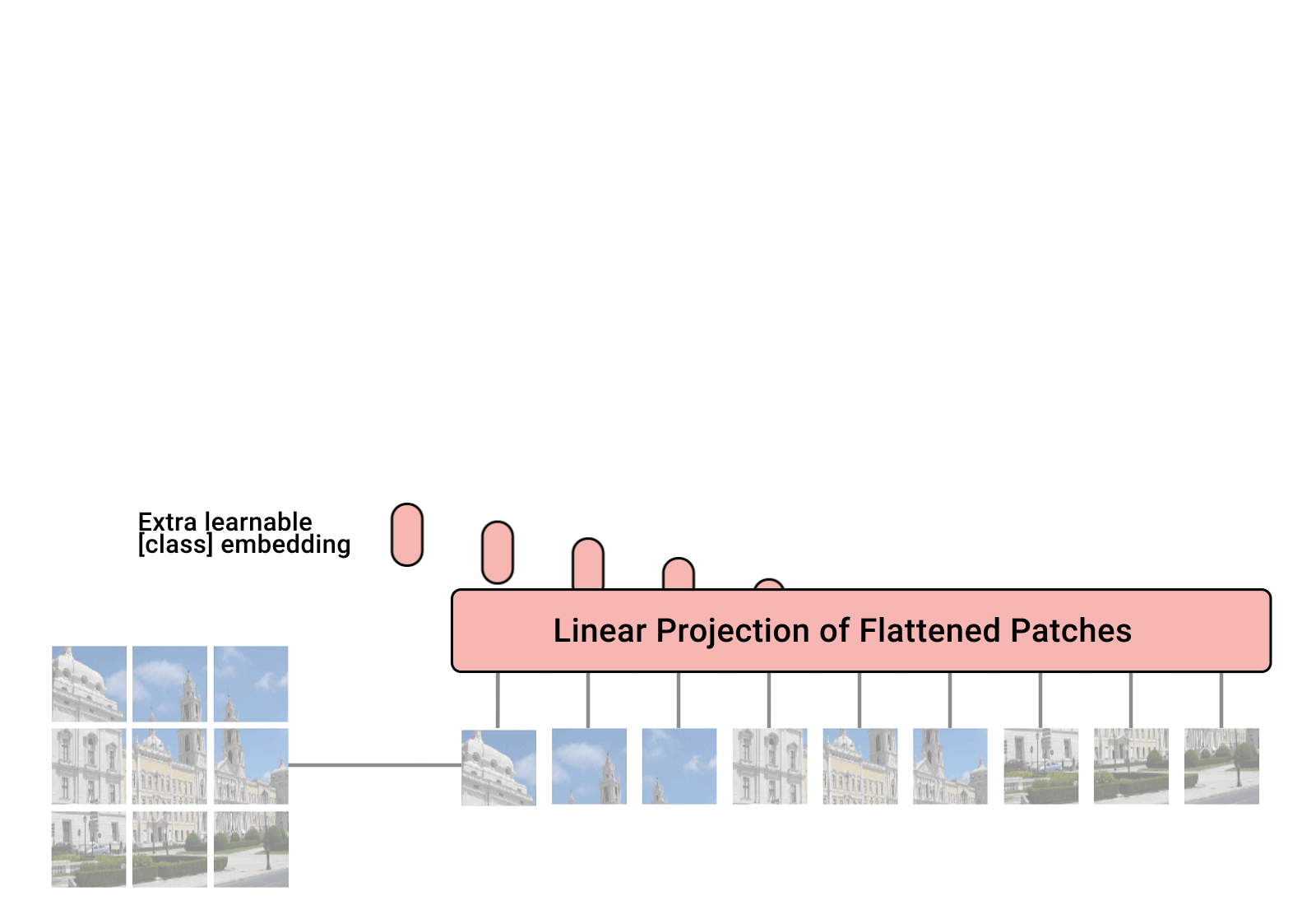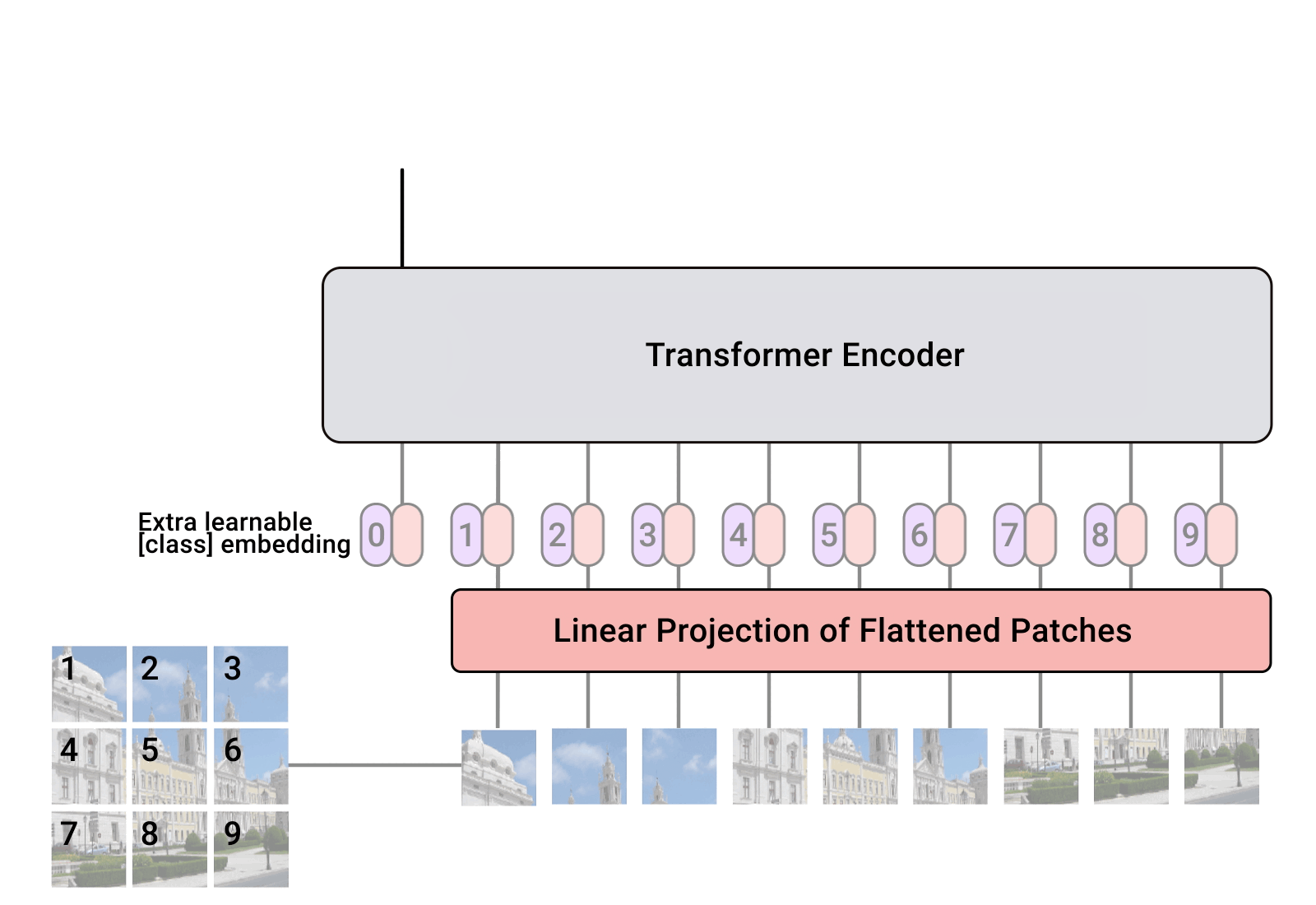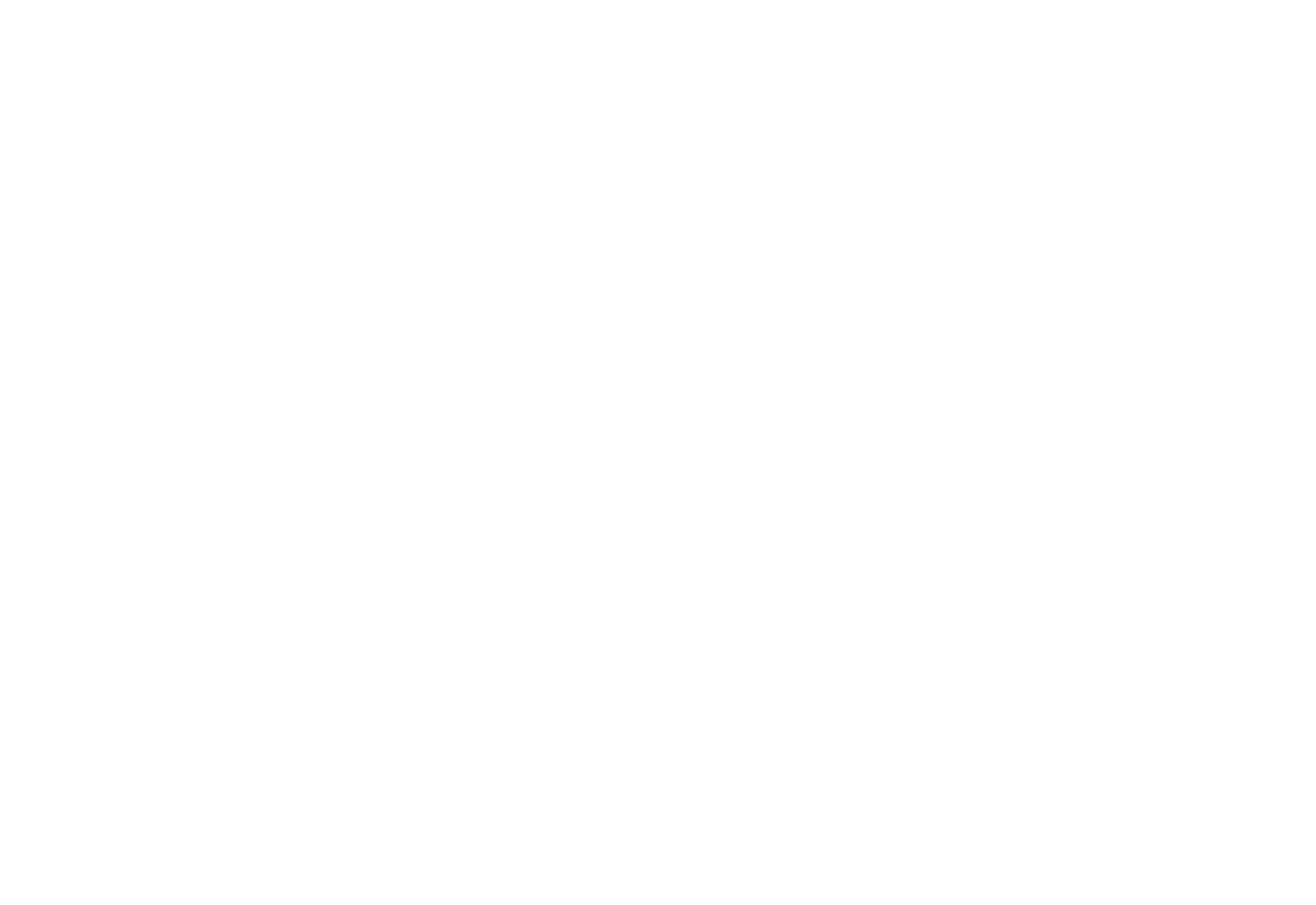
Vision Transformer는 하나의 이미지를 여러 개의 패치로 쪼개서 각각의 패치를 NLP 문장의 token 처럼 사용합니다. 모델이 입력 값을 처리하는 과정을 정리해보면 아래와 같습니다.
Step 1입력 이미지 $x \in \mathbb{R}^{H \times W \times C}$를 $N$개의 패치로 쪼갠 뒤 $x \in \mathbb{R}^{N \times (P^2 \cdot C)}$, sequence처럼 나열(flatten)합니다. ($P$는 패치의 크기)Step 2각각의 패치에 linear projection을 취해서 $D$차원에 매핑합니다. 이 projection의 output이 패치의 embedding입니다.Step 3패치 embedding에 position embedding $E_{pos}$을 더해서 input $z_0$을 만듭니다. (class token에 대한 embedding $x_{class}$도 학습되는 parameter)
Step 4input $z_0$을 Transformer Encoder에 입력합니다.Step 5Transformer Encoder의 output $z_L^0$에 MLP head를 연결하여 classification을 수행합니다. $z_L^0$은 이미지 representation과 같은 역할을 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
class VisionTransformer(nn.Module):
"""Vision Transformer as per https://arxiv.org/abs/2010.11929."""
def __init__(
self,
image_size: int,
patch_size: int,
num_layers: int,
num_heads: int,
hidden_dim: int,
mlp_dim: int,
dropout: float = 0.0,
attention_dropout: float = 0.0,
num_classes: int = 1000,
representation_size: Optional[int] = None,
norm_layer: Callable[..., torch.nn.Module] = partial(nn.LayerNorm, eps=1e-6),
conv_stem_configs: Optional[List[ConvStemConfig]] = None,
):
super().__init__()
_log_api_usage_once(self)
torch._assert(image_size % patch_size == 0, "Input shape indivisible by patch size!")
self.image_size = image_size
self.patch_size = patch_size
self.hidden_dim = hidden_dim
self.mlp_dim = mlp_dim
self.attention_dropout = attention_dropout
self.dropout = dropout
self.num_classes = num_classes
self.representation_size = representation_size
self.norm_layer = norm_layer
if conv_stem_configs is not None:
# As per https://arxiv.org/abs/2106.14881
seq_proj = nn.Sequential()
prev_channels = 3
for i, conv_stem_layer_config in enumerate(conv_stem_configs):
seq_proj.add_module(
f"conv_bn_relu_{i}",
Conv2dNormActivation(
in_channels=prev_channels,
out_channels=conv_stem_layer_config.out_channels,
kernel_size=conv_stem_layer_config.kernel_size,
stride=conv_stem_layer_config.stride,
norm_layer=conv_stem_layer_config.norm_layer,
activation_layer=conv_stem_layer_config.activation_layer,
),
)
prev_channels = conv_stem_layer_config.out_channels
seq_proj.add_module(
"conv_last", nn.Conv2d(in_channels=prev_channels, out_channels=hidden_dim, kernel_size=1)
)
self.conv_proj: nn.Module = seq_proj
else:
self.conv_proj = nn.Conv2d(
in_channels=3, out_channels=hidden_dim, kernel_size=patch_size, stride=patch_size
)
seq_length = (image_size // patch_size) ** 2
# Add a class token
self.class_token = nn.Parameter(torch.zeros(1, 1, hidden_dim))
seq_length += 1
self.encoder = Encoder(
seq_length,
num_layers,
num_heads,
hidden_dim,
mlp_dim,
dropout,
attention_dropout,
norm_layer,
)
self.seq_length = seq_length
heads_layers: OrderedDict[str, nn.Module] = OrderedDict()
if representation_size is None:
heads_layers["head"] = nn.Linear(hidden_dim, num_classes)
else:
heads_layers["pre_logits"] = nn.Linear(hidden_dim, representation_size)
heads_layers["act"] = nn.Tanh()
heads_layers["head"] = nn.Linear(representation_size, num_classes)
self.heads = nn.Sequential(heads_layers)
if isinstance(self.conv_proj, nn.Conv2d):
# Init the patchify stem
fan_in = self.conv_proj.in_channels * self.conv_proj.kernel_size[0] * self.conv_proj.kernel_size[1]
nn.init.trunc_normal_(self.conv_proj.weight, std=math.sqrt(1 / fan_in))
if self.conv_proj.bias is not None:
nn.init.zeros_(self.conv_proj.bias)
elif self.conv_proj.conv_last is not None and isinstance(self.conv_proj.conv_last, nn.Conv2d):
# Init the last 1x1 conv of the conv stem
nn.init.normal_(
self.conv_proj.conv_last.weight, mean=0.0, std=math.sqrt(2.0 / self.conv_proj.conv_last.out_channels)
)
if self.conv_proj.conv_last.bias is not None:
nn.init.zeros_(self.conv_proj.conv_last.bias)
if hasattr(self.heads, "pre_logits") and isinstance(self.heads.pre_logits, nn.Linear):
fan_in = self.heads.pre_logits.in_features
nn.init.trunc_normal_(self.heads.pre_logits.weight, std=math.sqrt(1 / fan_in))
nn.init.zeros_(self.heads.pre_logits.bias)
if isinstance(self.heads.head, nn.Linear):
nn.init.zeros_(self.heads.head.weight)
nn.init.zeros_(self.heads.head.bias)
def _process_input(self, x: torch.Tensor) -> torch.Tensor:
# n = batch size
# c = channel 개수
# h, w = 입력 이미지의 높이, 너비
n, c, h, w = x.shape
p = self.patch_size
torch._assert(h == self.image_size, f"Wrong image height! Expected {self.image_size} but got {h}!")
torch._assert(w == self.image_size, f"Wrong image width! Expected {self.image_size} but got {w}!")
# 입력 이미지의 높이(h), 너비(w)를 패치 길이(p)로 나눈 몫은 세로, 가로에 할당되는 패치 개수를 의미합니다.
# 따라서 n_h * n_w = 패치 개수(sequence length)가 됩니다.
n_h = h // p
n_w = w // p
# conv_proj 함수를 통해서 hidden_dim(D) 차원에 매핑합니다.
# (n, c, h, w) -> (n, hidden_dim, n_h, n_w)
x = self.conv_proj(x)
# (n, hidden_dim, n_h, n_w) -> (n, hidden_dim, (n_h * n_w))
x = x.reshape(n, self.hidden_dim, n_h * n_w)
# 입력 이미지를 (n_h * n_w)개의 패치로 쪼개어 나열합니다.
# (n, hidden_dim, (n_h * n_w)) -> (n, (n_h * n_w), hidden_dim)
# The self attention layer expects inputs in the format (N, S, E)
# where S is the source sequence length, N is the batch size, E is the
# embedding dimension
x = x.permute(0, 2, 1)
return x
def forward(self, x: torch.Tensor):
# Step 1, Step 2. _process_input 함수를 통해 패치 embedding을 만듭니다.
x = self._process_input(x)
n = x.shape[0]
# Step 3. torch.cat으로 (패치 embedding + position embedding)에 class token의 embedding을 연결합니다.
batch_class_token = self.class_token.expand(n, -1, -1)
x = torch.cat([batch_class_token, x], dim=1)
# Step 4. Step 3까지의 과정을 통해 얻은 input을 Encoder에 입력합니다.
x = self.encoder(x)
x = x[:, 0]
# Step 5. Encoder의 output을 MLP head에 연결합니다.
x = self.heads(x)
return x