[Paper Review] Attention is All You Need
Introduction
sequence modeling 관점에서 RNN과 Transformer를 비교해보면 다음과 같이 정리할 수 있습니다.
| Challenges with RNNs | Transformer Networks |
|---|---|
| 멀리 떨어진 단어들 간의 의존성을 학습하기 어려움 | 장기 의존성을 처리하기 용이함 |
| Gradient vanishing and explosion | No gradient vanishing and explosion |
| 학습 속도가 느림 | 상대적으로 학습 속도가 빠름 |
| 병렬처리 어려움 | 병렬처리 용이 |
이처럼 Transformer는 RNN이 지닌 문제점을 개선한 모델로, 논문 제목에서 알 수 있듯이 RNN 없이 attention만으로 encoder와 decoder를 구성했습니다. 최근 NLP 분야에서 높은 성능을 보여주고 있는 BERT와 OpenAI GPT도 Transformer 구조를 기반으로 만들어졌을 만큼 영향력이 매우 큰 모델입니다.
Model Architecture
![]()
Encoder
- encoder의 input은 단어 embedding + positional embedding입니다. 어떤 단어의 embedding에 위치에 따라 다른 positional embedding 값을 더하는 것입니다. RNN은 source sequence의 단어가 차례대로 입력되어야 하기 때문에 병렬처리가 어려운데요. Transformer는 단어 embedding에 positional embedding을 더해 주어 위치 정보를 담기 때문에 순서대로 입력하지 않아도 됩니다. 즉, source sequence를 한 번에 입력할 수 있으므로 병렬처리가 용이하다는 장점이 있습니다. 또한 같은 단어라도 문장에 따라 다른 의미를 가질 수 있는데, positional embedding을 사용하면 이를 구현할 수 있습니다. 즉, 문맥 정보를 담은 embedding을 구할 수 있는 것입니다.
- encoder는 6개 layer로 구성되는데, 각각의 layer는 2개의 sub layer를 갖습니다. 첫 번째 sub layer는 multi-head self-attention layer이고 두 번째는 position-wise fully connected feed-forward network입니다. 각각의 sub layer에 residual connection과 layer normalization을 적용하여 output은 $LayerNorm(x+Sublayer(x))$이고, output의 차원 $d_{model}=512$입니다.
Decoder
- decoder는 역시 6개 layer로 구성되는데, encoder와 같은 sub layer에 encoder output에 대한 multi-head attention을 수행하는(encoder-decoder attention) layer가 추가되어 총 3개의 sub layer를 갖습니다.
- 또한 decoder의 multi-head self-attention layer는 position $i$보다 뒤에 있는 position들을 masking해서 이미 알고있는 output을 바탕으로 position $i$을 예측하도록 했습니다.
Attention
Scaled Dot-Product Attention
query$Q$와 모든key$K$의 dot product를 구한 뒤 scaling factor $\sqrt{d_k}$로 나누어서 value $V$에 대한 가중치를 얻습니다. scaling factor $\sqrt{d_k}$로 나누는 것은,query와key의 dimension $d_k$가 크면 dot-product 값이 커져서 softmax 함수의 gradient가 너무 작아지기 때문에 이를 막기 위함입니다.
Multi-Head Attention
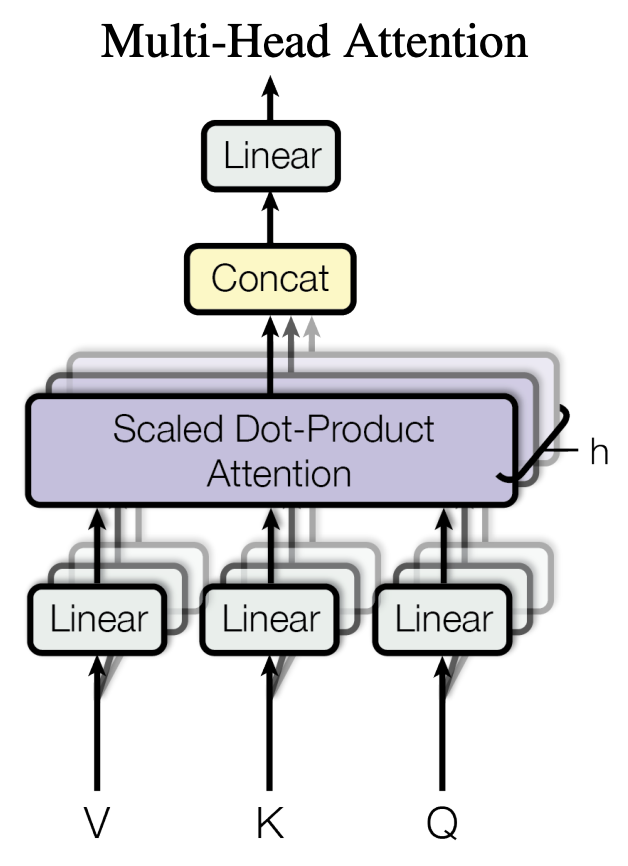
- multi-head attention은 input embedding을 여러 개로 쪼개어서 각각 attention을 수행하는 구조입니다.
- 이 구조를 사용하면 h개의 서로 다른 attention 컨셉을 학습할 수 있습니다.
- 본 논문에서는 $d_{model}=512$, $h=8$을 적용하였는데요. 이 경우 8개의 head 각각에서 Scaled Dot-Product Attention에 사용되는
query,key,value의 dimension은 $d_k=d_v=d_{model}/h=64$가 됩니다. 그리고 8개의 attention 결과 값을 concatenate 한 뒤 linear projection을 거칩니다.
- multi-head attention을 수행한 뒤에도 출력 값의 dimension이 동일하게 유지됩니다.
Applications of Attention in our Model
Transformer에서는 multi-head attention을 세 가지 방법으로 구분해서 사용합니다.
encoder-decoder attention layer
encoder-decoder attention layer에서는 decoder layer의 output이 query로 사용되고, encoder의 output이 key와 value로 사용됩니다. 각각의 decoder position이 source sequence의 어느 부분과 관련성이 큰지 학습하는 부분으로, 전형적인 encoder-decoder attention 모델의 메커니즘을 모방한 것입니다. (이전 포스트)
encoder self-attention
encoder의 self-attention에서는 encoder layer의 output이 query, key, value로 사용되어 source sentence 내 단어들 간의 attention 값을 계산할 수 있습니다.
masked decoder self-attention
masked decoder self-attention에서는 decoder layer의 output이 query, key, value로 사용되어 target sentence 내 단어들 간의 attention 값을 계산할 수 있습니다. +position $i$보다 뒤에 있는 position들을 masking
Why Self-Attention
self-attention
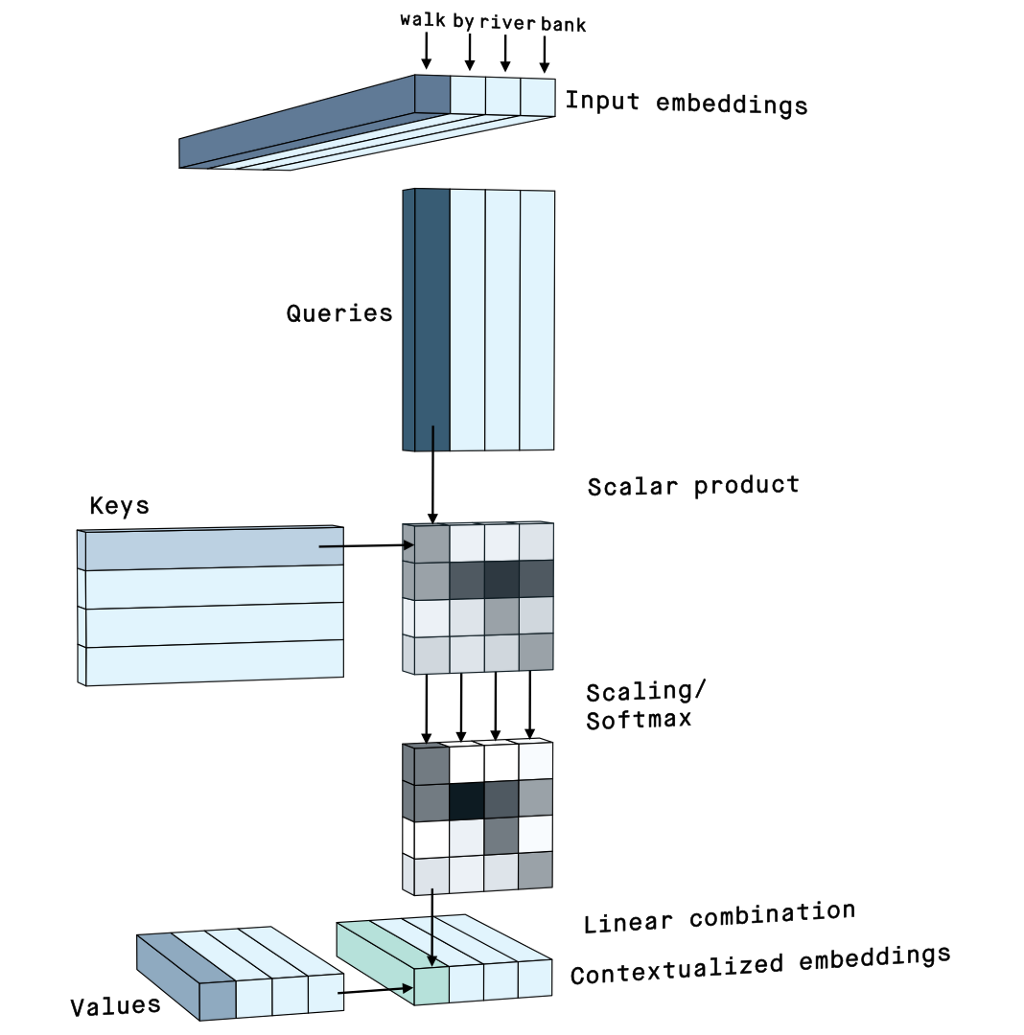
위 이미지에서 확인할 수 있듯이, self-attention은 attention에 사용되는 Query, Key, Value는 동일 문장 내의 토큰을 가리킵니다. Bahdanau et al. 2014에서 decoder의 output과 encoder의 output을 각각 Query, Key로 두고, 두 output의 유사도를 산출하여 encoder의 output Value에 대한 가중치로 사용한 것과는 다르다는 점을 알 수 있습니다. 동일 문장 내 토큰들 사이의 attention 가중치를 계산하는 것은 어떤 의미를 지닐까요?
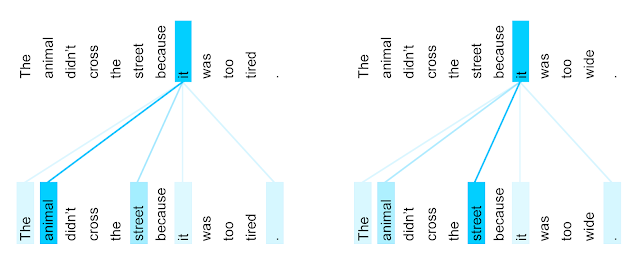
위 예시는 encoder self-attention 분포를 나타낸 이미지입니다. 두 문장은 맨 마지막 토큰 tired와 wide만 다른 문장이고, 이 차이로 인해서 두 문장의 it은 서로 다른 대상을 가리킵니다. self-attention을 통해 각각의 문장이 가리키는 대상에 큰 가중치가 부여된 것을 확인할 수 있습니다. 모델이 문장의 문맥을 이해할 수 있게 되는 것입니다.
이와 함께 본 논문에서 제시한 self-attention의 다른 이점들은 다음과 같습니다.

- layer당 연산 복잡도가 낮음
- 병렬처리가 가능한 연산량이 많음
- long-range dependency를 처리하기 용이함
Training
- Optimizer
- Adam optimizer
- 첫 4000 step 동안은 learning rate를 선형적으로 증가시키다가 그 이후에는 $step_num^{-0.5}$에 비례하여 감소시킴
- Regularization
- Residual Dropout
- sub layer의 output $Sublayer(x)$에 dropout 적용
- embedding과 positional encoding의 합에 dropout 적용
- Label Smoothing
- Residual Dropout