[Paper Review] DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
이번 포스트에서는 semantic segmentation 모델인 DeepLabV1과 DeepLabV2를 함께 리뷰해 보려고 합니다. 먼저 DeepLabV1은 LC Chen et al. 2016에서 제안된 모델인데요. DeepLabV1을 자세히 알아보기 전에, 대표적인 선행 연구인 Fully Convolutional Network(FCN)과의 차이점을 먼저 짚고 넘어가겠습니다.
Fully Convolutional Network과의 차이점
첫번째로 DeepLabV1은 semantic segmentation을 위해 Deep CNN만 사용한 것이 아니라 fully connected CRFs를 함께 사용했습니다. 이러한 결합 구조를 사용한 이유를 이해하기 위해서는 먼저 Deep CNN 고유의 특성을 이해하는 것이 필요합니다.
Deep CNN은 레이어를 깊게 쌓아 올려 이미지로부터 추상적인 feature를 추출할 수 있습니다. 그래서 input 내 물체의 위치가 변해도 함수의 output이 변하지 않는 invariance 특성을 갖습니다. invariance 특성은 high-level task에서는 성능을 높이는 역할을 하지만, semantic segmentation같은 low-level task에서는 방해 요소입니다. semantic segmentation은 정밀한 localization이 핵심인데, 추상적인 feature를 바탕으로 구한 segmentation 결과 값은 정확도가 떨어지기 때문입니다.
FCN도 이러한 한계점을 보완하기 위해 깊은 레이어의 feature에 얕은 레이어의 feature를 더해주는 layer fusion 방식을 사용했었는데요. DeepLabV1에서는 post-processing 방법으로 fully connected CRFs을 사용했습니다. 모든 픽셀을 CRF 노드로 취급해 연결함으로써 지역적 상관관계를 잡아낼 수 있도록 했습니다.
두번째로 DeepLabV1은 FCN과 달리 hole algorithm(atrous convolution)을 사용했습니다. 앞에서 언급한 것처럼 Deep CNN은 max pooling과 downsampling을 반복하면서 점차 추상적인 low-resolution feature를 추출합니다. 결과적으로 coarse score를 얻게 되는데요. fine score를 얻기 위해 stride를 줄여서 resolution이 감소하는 것을 통제할 수도 있지만, pre-trained VGG16을 기본 구조로 사용하는 FCN에서는 이 방법을 적용하기 어렵습니다. stride를 2에서 1로 줄이면 receptive field 크기를 유지하기 위해 kernel 크기가 $7 \times 7$에서 $14 \times 14$로 커져야 하기 때문입니다. 이렇게 kernel 크기가 커지면 연산 비용도 증가하고, 학습하기도 어렵다는 문제가 있습니다.
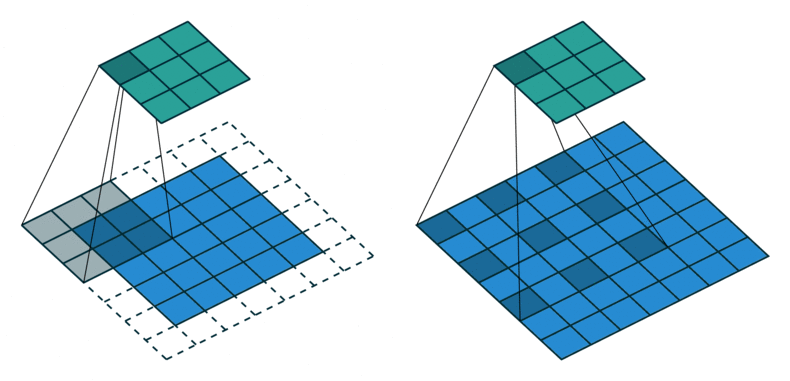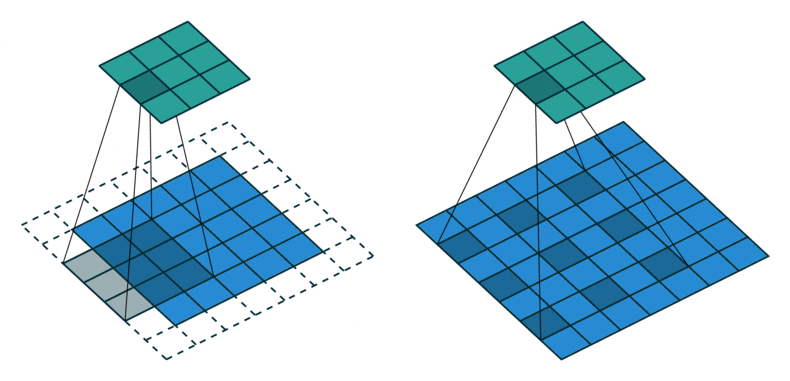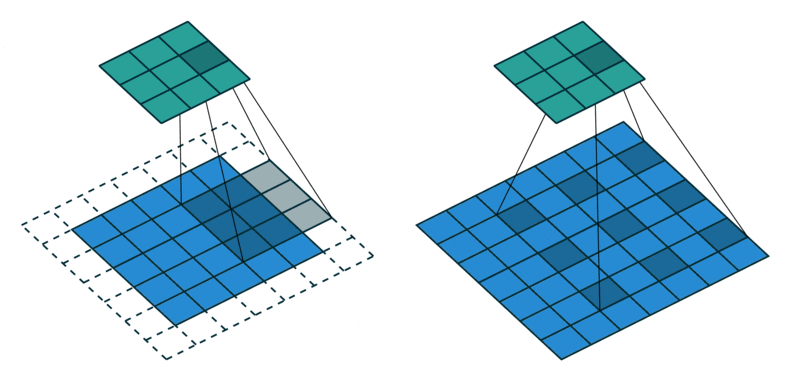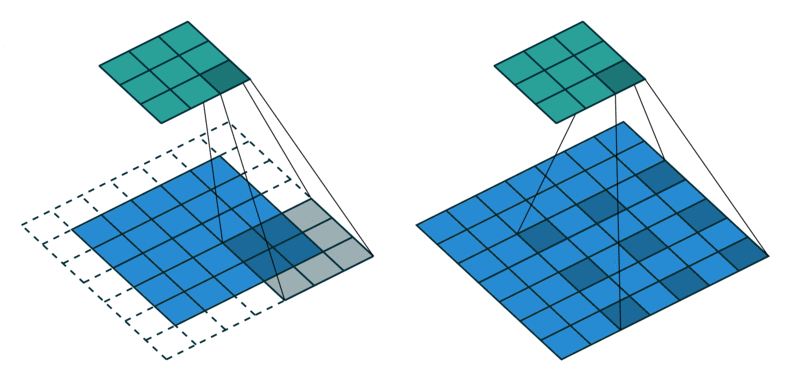 [왼쪽] 일반적인 convolution [오른쪽] atrous convolution
[왼쪽] 일반적인 convolution [오른쪽] atrous convolution
반면에 DeepLabV1에서 사용한 hole algorithm(atrous convolution)은 일반적인 convolution과 같은 크기의 kernel로 훨씬 넓은 receptive field를 커버할 수 있습니다. 오른쪽 atrous convolution은 kernel 크기가 $3 \times 3$, dilation이 2인 경우를 보여주는데요. (일반적인 convolution은 diltation이 1) dilation을 더 키워서 보다 넓은 receptive field를 커버하게 만들 수도 있습니다. 다시 말해 hole algorithm(atrous convolution)을 사용하면 stride를 1로 줄여서 resolution이 크게 감소하는 것을 막아 fine score를 얻으면서도, 동시에 연산 비용을 합리적으로 유지할 수 있습니다.
DeepLabV1 구조
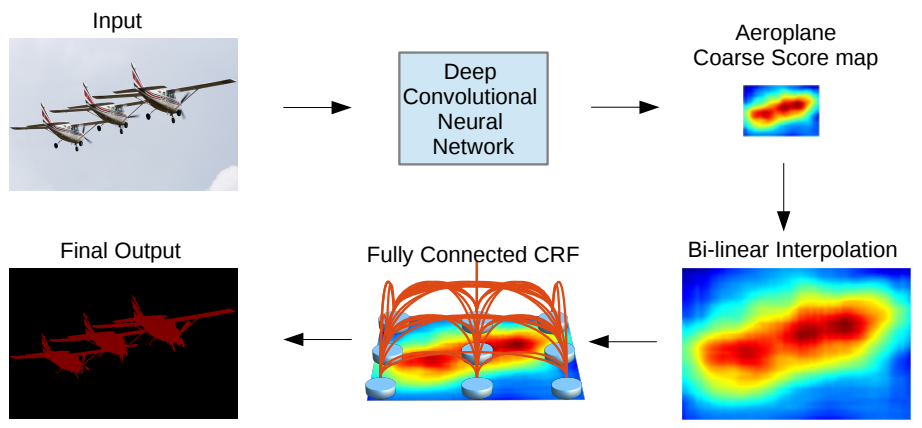
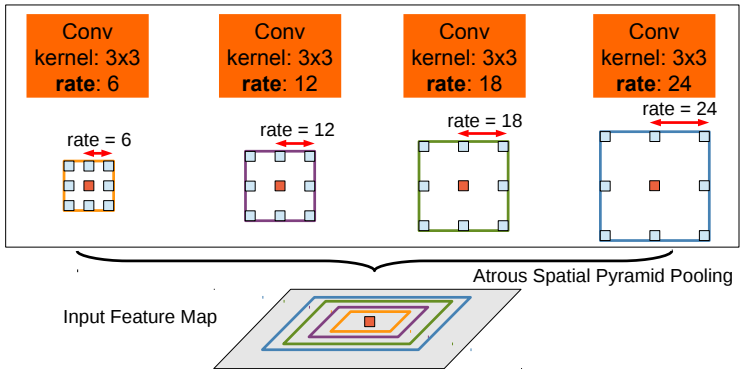
DeepLabV2 구조
DeepLabV2는 DeepLabV1에서 Atrous Spatial Pyramid Pooling(ASPP) 구조를 추가했습니다.