[Paper Review] Fully Convolutional Networks for Semantic Segmentation
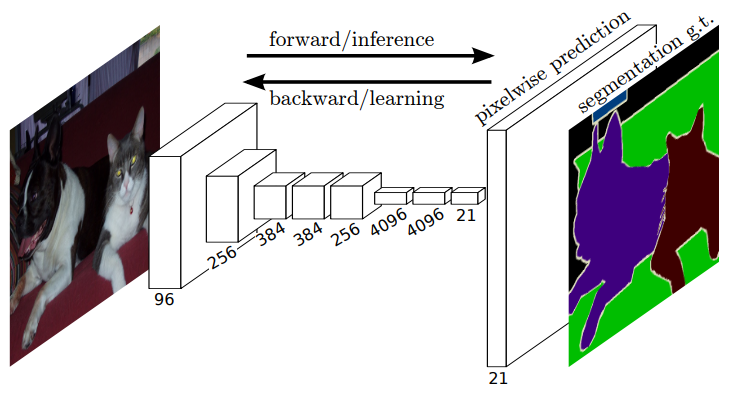 fully convolutional network 구조
fully convolutional network 구조
이미지 classification 모델로 널리 알려진 AlexNet, VGGNet 같은 모델의 구조를 생각해보면, 몇 개의 convolution + pooling layer를 반복적으로 거친 뒤에 그 결과로 얻은 feature map을 fully connected layer를 연결합니다. 이와 달리 fully convolutional networks는 위 그림에서 볼 수 있듯이 fully connected layer 없이 convolution layer만으로 이루어진 모델입니다. 본 논문에서 제안하는 fully convolutional networks의 구조와 그 성과에 대해 자세히 알아보기 전에, fully connected layer를 convolution layer로 대체하는 것이 어떤 의미를 갖는지 알아보겠습니다.
Fully Connected Layer를 Convolution Layer로 대체하면 어떤 일이 일어날까?
먼저, fully connected layer는 고정된 길이의 vector를 입력받아야 합니다. 이는 입력 이미지가 convolution 연산을 거친 뒤에 항상 같은 크기의 feature map을 생성해야 한다는 의미이므로, 입력 사이즈가 고정될 수밖에 없습니다. 하지만 fully convolutional network는 convolution 구조만으로 이루어져 있기 때문에 어떤 사이즈의 이미지든 처리할 수 있습니다.
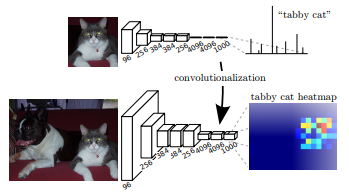 fully connected layer를 convolution layer로 대체
fully connected layer를 convolution layer로 대체
두번째로, 마지막에 fully connected layer를 사용하면 위치 정보를 잃게 됩니다. convolution layer를 통해 얻은 feature map을 column vector로 펼쳐서(flatten) fully connected layer에 입력하기 때문인데요. 이러한 특징은 classificaion task에서는 큰 문제가 되지 않을 수 있습니다. 하지만 segmentation task에서는 물체의 정확한 외곽선을 검출해야 하기 때문에 위치 정보가 매우 중요합니다. 따라서 fully connected layer를 convolution layer로 대체함으로써 위치 정보를 보존해야 하는 것입니다.
마지막으로, fully connected layer를 convolution layer로 대체하면 이미지 처리 속도가 훨씬 빨라집니다.
Fully Convolutional Network 구조
CNN은 레이어가 깊어질수록 다양한 resolution을 가진 feature를 추출할 수 있습니다. 얕은 레이어에서는 구체적이고 지역적인 정보를, 깊은 레이어에서는 추상적이고 글로벌한 정보를 얻습니다. 본 논문에서는 이러한 CNN의 장점을 적극 활용하여 semantic segmentation을 수행하는 fully convolutional network(FCN)를 제안합니다.
최근 이미지 classification 분야에서 우수한 성능을 보여준 CNN 모델의 pre-trained weight를 불러와서 fully connected layer를 convolution layer로 바꾼 뒤 fine-tuning하는 방식을 사용했는데요. 저자들은 여러 모델들 중 VGG16을 선택했습니다. 이 때, pre-trained VGG16 모델은 supervised 방식으로 학습한 모델입니다.
논문에서 제시된 그림과 pytorch 구현 코드를 바탕으로 모델 구조를 자세히 살펴보겠습니다. 얕은 레이어로부터 얻은 appearance 정보와 깊은 레이어로부터 얻은 semantic 정보를 결합해주는(layer fusion) skip architecture가 핵심 구조입니다.
 skip architecture
skip architecture
- 그림의
conv6과conv7이 코드 상에서fc6과fc7로 표현되어 있습니다. - 아래 과정에서 언급되는 $1 \times 1$ conv는 모두 21개의 채널을 갖는데요. 여기서 21은 class의 개수입니다. segmentation 모델은 아래 이미지와 같이 pixel별 class 분류 결과를 산출해야 하기 때문입니다.
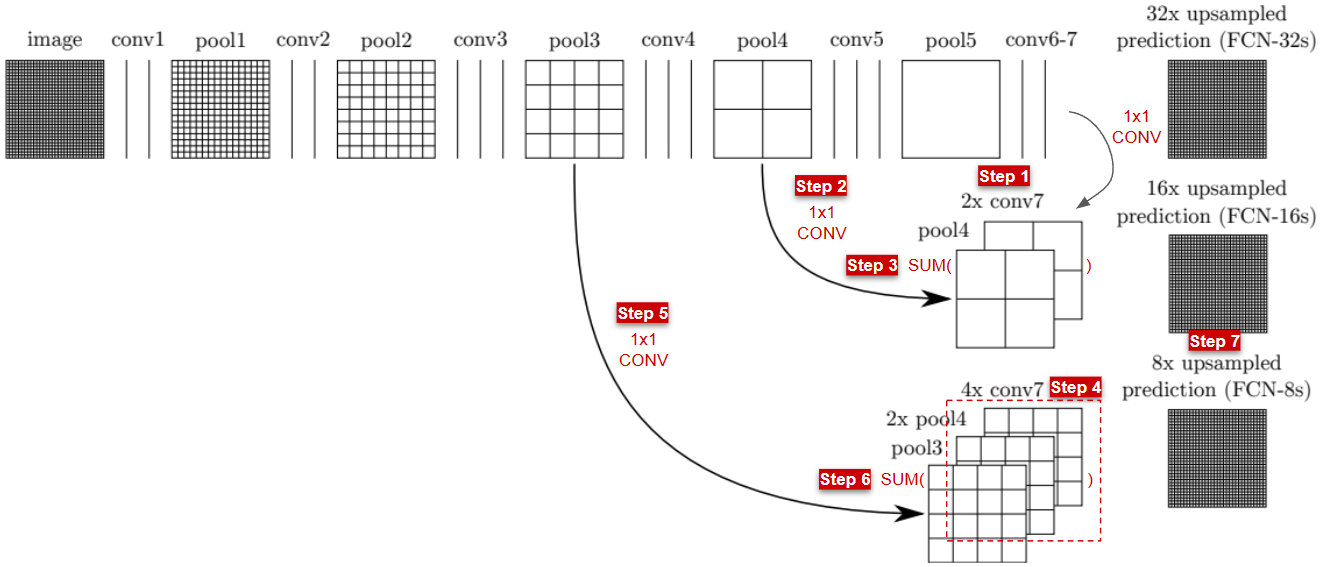
- FCN-8s를 구하는 과정은 아래와 같습니다.
Step 1conv7의 output feature map에 $1 \times 1$ conv를 적용한 뒤, 2배 upsampling 합니다.Step 2pool4의 output feature map에 $1 \times 1$ conv를 적용합니다.Step 3Step 1과Step 2을 더합니다.Step 4Step 3을 2배 upsampling 합니다. (2x pool4, 4x conv7)Step 5pool3의 output feature map에 $1 \times 1$ conv를 적용합니다.Step 6Step 4와Step 5를 더합니다.Step 7Step 6을 8배 upsampling 합니다.
실험 결과


- 여러 레이어에서 얻은 정보를 결합해 나갈수록 Ground truth에 가까운, 정교한 segmentation이 가능해 지는 것을 확인할 수 있습니다.
- 또한 마지막 레이어만 fine-tuning(FCN-32s-fixed) 했을 때보다 전체 레이어를 fine-tuning 했을 때 정확도가 더 높았습니다.