[Paper Review] Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection
MahalanobisAD는 정상 이미지들의 feature를 multivariate Gaussian(MVG) 분포에 fitting 시켜서 정상성을 정의합니다. 이 때, feature는 ImageNet 데이터셋으로 pretrain한 CNN 모델에 이미지를 통과시켜 추출합니다. 그리고 테스트 이미지와 multivariate Gaussian(MVG) 분포 사이의 Mahalanobis 거리를 산출하여 anomaly score를 구합니다. 또한, 저자들은 본 논문에서 pretrained CNN을 사용해 추출한 feature들의 특징을 Principal Component Analysis(PCA)를 통해 설명합니다. 본 포스트에서는 MahalanobisAD가 이상탐지를 진행하는 과정을 살펴보고, MVTec 데이터셋으로 평가한 모델 성능을 SPADE와 비교해 보겠습니다.
이상탐지 진행 과정
1. Feature Extraction
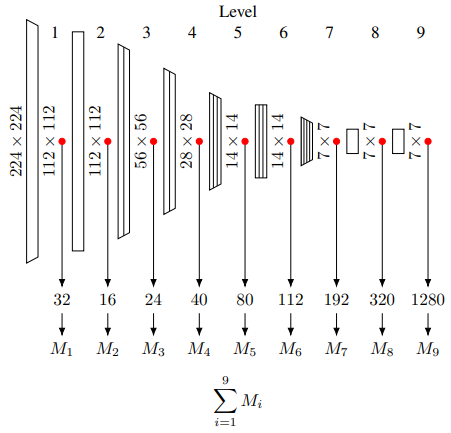 EfficientNet의 경우 feature extraction 과정
EfficientNet의 경우 feature extraction 과정
가장 먼저 정상 이미지들의 feature를 추출합니다. 각 block의 마지막 feature map을 추출해서 더한 값을 이미지의 feature로 사용했는데요. 본 논문에서 feature 추출에 사용한 pretrained CNN은 EfficientNet과 ResNet이고, 별도의 fine-tuning 과정은 거치지 않았습니다.
2. Modeling Nomal Data Distribution in Deep Feature Representations
평균 $\mu$와 공분산 $\Sigma$를 갖는 Gaussian 분포와 특정 point $\mathbf{x} \in \mathbb{R}^D$ 사이의 Mahalanobis 거리는 다음과 같이 정의할 수 있습니다.