[Paper Review] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
Introduction
semantic segmentation은 image classification의 연장선에 있다고 볼 수 있습니다. 우리가 흔히 알고 있는 image classification은 이미지 단위 classification이고, semantic segmentation은 픽셀 단위 classification이기 때문입니다. 이런 연유로 Long et al. 2015에서 semantic segmentation 수행을 위해 fully convolutional networks (FCNs)을 사용한 이후, FCN은 semantic segmentation 분야의 지배적인 구조로 자리잡았습니다. 두 분야의 높은 관련성 때문에 최신 semantic segmentation 모델들은 image classsification에서 널리 사용되는 구조의 변형인 경우가 많았습니다. 이에 따라 backbone 구조 설계에 대한 연구가 활발히 진행되어 왔으며, 이 과정에서 semantic segmentation 분야의 성능이 크게 향상했습니다. 또한 문맥 정보를 효과적으로 추출하는 구조를 설계하는 것도 중요한데요. 대표적인 예가 kernel에 구멍을 내어 receptive field를 확장하는 구조인 dilated convolution 입니다.
NLP 분야에서 Transformer가 큰 성공을 거둔 뒤로, 많은 연구자들이 vision 분야에 Transformer를 적용한 모델을 제안해 왔습니다. semantic segmentation에서는 SETR 모델이 좋은 성능을 보여주긴 했지만, backbone으로 쓰인 Vision Transformer는 아래와 같은 한계점을 가지고 있습니다.
- 한 가지 크기의 low-resolution feature map을 생성함
- 이미지 사이즈가 큰 경우 연산 비용이 너무 큼
이에 따라, 서로 다른 크기의 feature를 생성하는 Transformer들을 쌓아 올리는 pyramid vision Transformer(PVT)가 제안되었는데요. PVT 기반 모델들의 장단점을 정리해 보면 아래와 같습니다.
- 장점
- feature들의 local continuity 향상
- 고정된 크기의 position embedding 제거
- 단점
- 주로 Transformer encoder 설계에 집중했고 decoder의 역할을 간과
이러한 배경으로, 본 논문에서는 hierarchical Transformer encoder와 MLP decoder로 구성된 semantic segmentation 모델인 SegFormer를 제안합니다. hierarchical Transformer encoder는 CNN처럼 다양한 크기의 feature map을 생성하고, MLP decoder는 여러 layer의 정보를 종합하여 local attention과 global attention을 결합함으로써 유용한 representation을 생성하는 역할을 한다고 합니다. Method 파트에서 모델 구조를 좀 더 자세히 살펴 보겠습니다.
Method
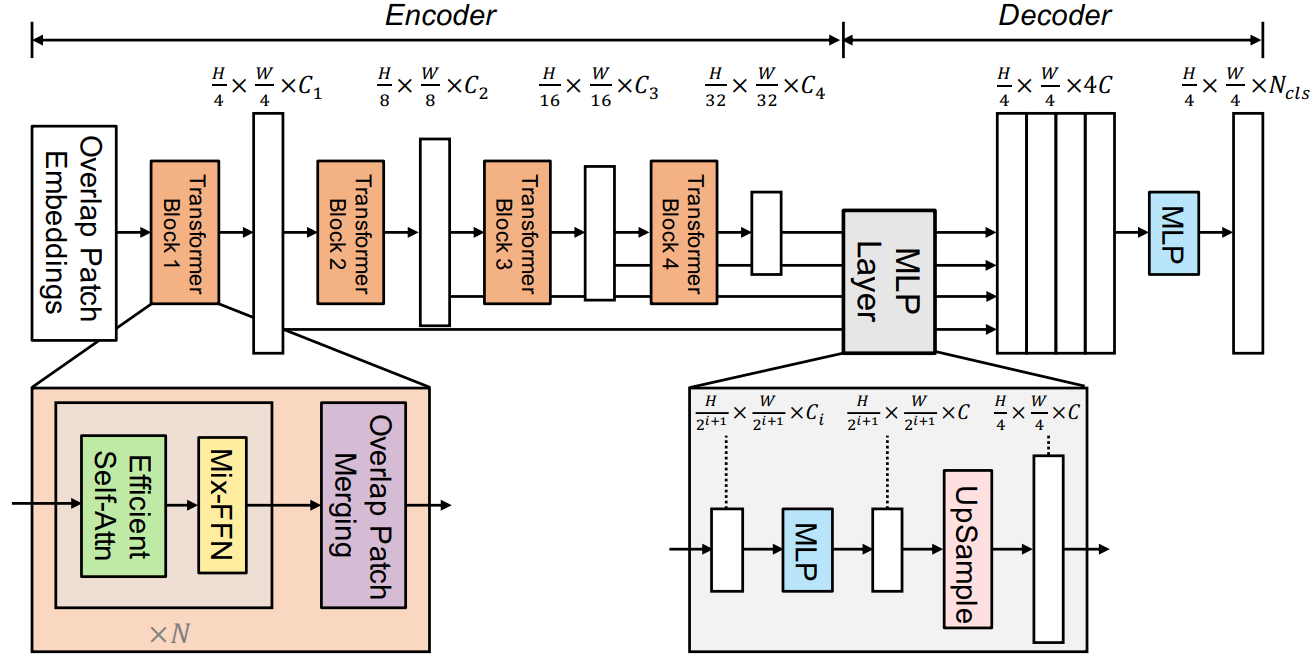
1. Hierachical Transformer Encoder
Hierachical Transformer Encoder가 입력 값을 처리하는 과정을 정리해 보면 아래와 같습니다.
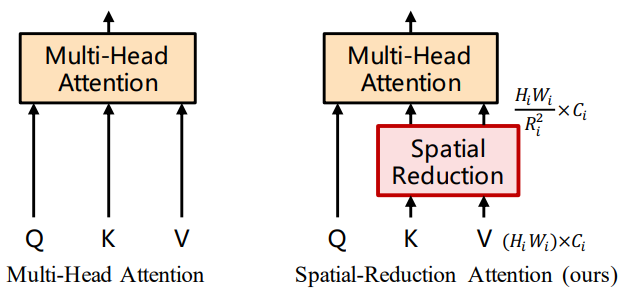
Step 1[Overlap Patch Embedding] $ H \times W \times 3 $ 사이즈를 갖는 입력 이미지를 $ 4 \times 4 $ 사이즈의 패치들로 쪼개어 embedding 합니다. Vision Transformer에서는 패치 사이즈로 $ 16 \times 16 $을 사용했는데, 작은 패치 사이즈를 사용하면 픽셀 단위 예측에 보다 유리합니다. 만약 non-overlap patch embedding을 한다면 $ 4 \times 4 $ conv를 stride 4로 수행하면 될 것 같습니다. 하지만 본 논문에서는 이러한 non-overlap 방법이 패치 주변의 지역적 연속성(local continuity)를 보존하지 못하게 한다고 지적합니다. 이에 따라 overlap 방법을 사용하기 위해 $ 7 \times 7 $ conv를 stride 4, padding 3으로 수행합니다. 예를 들어 입력 이미지의 사이즈가 $ 512 \times 512 \times 3 $ 이고, embedding dimension이 64이면 overlap patch embedding의 output dimension은 $ 128 \times 128 \times 64 $가 됩니다.Step 2[Efficient Self-Attention] self-attention layer는 encoder의 주요 computation bottleneck입니다. 이미지 사이즈의 제곱에 비례하여 연산 복잡도가 증가하기 때문인데요. 더욱이 Vision Transformer보다 작은 패치 사이즈를 사용하면서 패치의 개수가 더 많아졌기 때문에, self-attention을 그대로 사용하면 연산 비용이 급격히 증가할 것입니다. 이러한 문제를 해결하기 위해 reduction ratio $R$을 사용하여 sequence의 길이 $ N=H \times W $을 줄이는 과정이 바로 Efficient Self-Attention입니다. 아래 수식대로 진행하면 최종적으로 $K$의 dimension은 $\frac{N}{R} \times C$가 됩니다. 본 논문에서는 Stage 1부터 Stage 4까지의 reduction ratio를 [64, 16, 4, 1]로 설정했습니다.
Step 3[Mix-FFN] Vision Transformer는 고정된 positional encoding (PE)를 사용하는데요. 이런 경우 train 이미지와 resolution이 다른 이미지를 테스트할 때 positional code를 interpolation 하는 과정을 거쳐야 하고, 그 결과 성능이 하락한다는 단점이 있습니다. 본 논문에서는 고정된 PE를 사용할 필요 없이, $ 3 \times 3 $ depthwise conv를 사용하면 Transformer에 위치 정보를 전달하기에 충분하다고 주장합니다. depthwise conv를 사용한 이유는 파라미터 개수를 줄여 효율성을 높이기 위함입니다. (아래 수식에서 $x_{in}$은Step 2self-attention layer의 output입니다.)
Step 4[Overlap Patch Merging]Step 1와 같은 방법으로 overlap patch merging을 수행하는데, 이 때 kernel size는 $ 3 \times 3 $, stride는 2, padding은 1입니다.Step 2부터Step 4를 반복합니다. 입력 이미지의 사이즈가 $ 512 \times 512$이고 embedding dimension이 64일 때의 진행 과정을 정리하면 아래와 같습니다.Step 1부터Step 3이 Stage 1에 대응하는 과정입니다.
| input size | kernel size | stride | padding | embed dim $C$ | output size | |
|---|---|---|---|---|---|---|
| Stage 1 | $512 \times 512 \times 3$ | $ 7 \times 7 $ | 4 | 3 | 64 | $128 \times 128 \times 64 \, (\frac{H}{4} \times \frac{W}{4} \times C_1)$ |
| Stage 2 | $128 \times 128 \times 64$ | $ 3 \times 3 $ | 2 | 1 | 128 | $64 \times 64 \times 128\, (\frac{H}{8} \times \frac{W}{8} \times C_2)$ |
| Stage 3 | $64 \times 64 \times 128$ | $ 3 \times 3 $ | 2 | 1 | 320 | $32 \times 32 \times 320\, (\frac{H}{16} \times \frac{W}{16} \times C_3)$ |
| Stage 4 | $32 \times 32 \times 320$ | $ 3 \times 3 $ | 2 | 1 | 512 | $16 \times 16 \times 512\, (\frac{H}{32} \times \frac{W}{32} \times C_4)$ |
2. Lightweight All-MLP Decoder
Decoder가 Encoder의 output을 전달 받아 처리하는 과정은 아래와 같습니다.
Step 1hierarchical Transformer encoder에서 생성한 multi-level feature를 MLP layer에 통과시켜 embedding dimension을 $C$로 일치시킵니다.Step 2Step 1의 output을 up-sampling한 뒤 이어 붙입니다(concat).Step 3Step 2의 output을 MLP layer에 입력합니다.Step 4Step 3의 output을 또다른 MLP layer에 입력하여 최종적으로 $\frac{H}{4} \times \frac{W}{4} \times N_{cls}$ 크기를 갖는 segmentation mask $M$을 얻습니다. ($N_{cls}$은 카테고리의 개수입니다.)