[Paper Review] Towards Total Recall in Industrial Anomaly Detection
PatchCore는 SPADE와 PaDiM의 특징을 합친 모델로, SPADE의 Gallery와 비슷한 역할을 하는 Memory Bank를 사용합니다. 또한 PaDiM처럼 patch level 접근법을 사용하는데, 이웃한 pixel feature들을 묶어서 patch feature를 만든다는 것이 PaDiM과의 차이점입니다. 테스트 시에 테스트 이미지의 patch feature들과 Memory Bank에 저장된 patch feature들의 거리를 계산하여 비교하기 때문에, 정상 이미지의 특징을 압축하여 표현할 수 있는 고품질의 Memory Bank를 구성하는 것이 무엇보다 중요한 모델입니다. 본 포스트에서는 PatchCore가 이상탐지를 진행하는 과정과 함께 MVTec 데이터셋으로 모델 성능을 평가한 결과를 살펴보겠습니다.
이상탐지 진행 과정
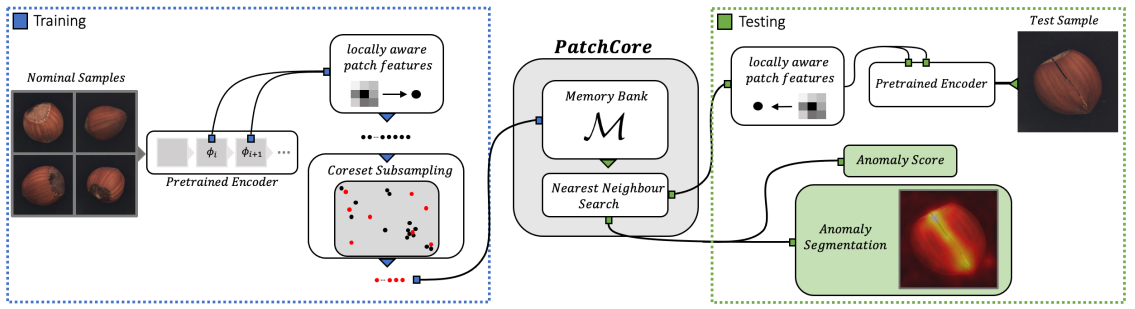 PatchCore 이상탐지 진행 과정
PatchCore 이상탐지 진행 과정
1. Locally aware patch features
첫 번째 단계는 정상 이미지들의 feature를 추출하는 단계입니다. 위 이미지의 ‘Pretrained Encoder’ 부분에 나타나 있는데요. ImageNet 데이터셋으로 pre-train한 CNN을 $\phi$라고 하면, 입력이미지 $x_i$를 pre-trained CNN에 입력해서 얻은 $j$번째 block의 output은 다음과 같이 나타낼 수 있습니다. $c^* $는 depth(channel 수), $h^* $와 $w^* $는 각각 높이와 너비를 의미합니다.
\[\phi_{i,j}=\phi_j(x_i), j=\{ 1,2,3,4 \}\] \[\phi_{i,j}= \in \mathbb{R}^{h^* \times w^* \times c^*}\]본 논문에서는 지나치게 추상적이거나 ImageNet 데이터셋에 편향된 feature가 추출되는 것을 막기 위해 중간 layer의 feature들을 추출해 합쳤는데요. ($j=[2,3]$) $j$번째 block의 output $\phi_{i,j}$과 $j+1$번째 block의 output $\phi_{i,j+1}$은 크기가 다르기 때문에 $\phi_{i,j+1}$에 bilinear interpolation을 취해서 크기를 맞춰준 다음 concatenate 합니다.
다음으로는 이 feature들로 locally aware patch feature를 만듭니다. 특정 위치 $(h,w)$를 중심으로 patch size만큼의 주변 feature vector들을 neighborhood로 묶은 다음, adaptive average pooling을 취해서 만드는데요. 논문에서 사용한 patch size $p=3$이고, striding parameter $s=1$입니다. 이는 개별 feature map들에 대한 local smoothing 과정이라고 볼 수 있습니다. 위 이미지의 ‘locally aware patch features’ 부분을 보면 $3 \times 3$ 크기의 feature vector들을 묶어서 adaptive average pooling을 거쳐 하나의 patch feature를 만드는 과정이 표현되어 있습니다. locally aware patch feature의 장점을 정리해 보면 아래와 같습니다.
- sliding window를 사용한 것처럼 주변 context를 고려한 feature map을 만들 수 있습니다.
- 이미지 내의 작은 위치 변화나 왜곡이 발생하더라도 일관적인 feature를 추출할 수 있어 일반화 성능이 향상됩니다.
- 해상도를 유지하면서 동시에 feture를 효과적으로 추출할 수 있습니다. 이는 특히 고해상도 이미지나 복잡한 시각적 패턴이 있는 분야에서 중요합니다.
2. Coreset-reduced patch-feature memory bank

두 번째 단계는 Memory Bank $\mathcal{M}$를 구성하는 단계입니다. 첫 번째 단계에서 생성한 모든 patch feature로 Memory Bank를 구성하면 굉장히 큰 저장 공간이 필요할 것입니다. 그리고 테스트 과정에서는 테스트 이미지의 patch feature들을 Memory Bank의 patch feature와 비교해야 하는데, Memory Bank가 지나치게 크면 많은 연산 시간이 소요되어 소요되어 현실적으로 사용하기가 어렵습니다.
이러한 이유로 본 논문에서는 Coreset Subsampling 기법을 사용하여 전체 데이터셋을 잘 대표할 수 있는 핵심 patch feature만 추출해 Memory Bank를 구성합니다. 이렇게 하면 저장 공간을 절약하고 계산 효율성도 높일 수 있습니다. sampling에는 greedy coreset selection 방법을 사용하는데요. 이를 의미하는 아래 수식을 좀 더 자세히 살펴보겠습니다.
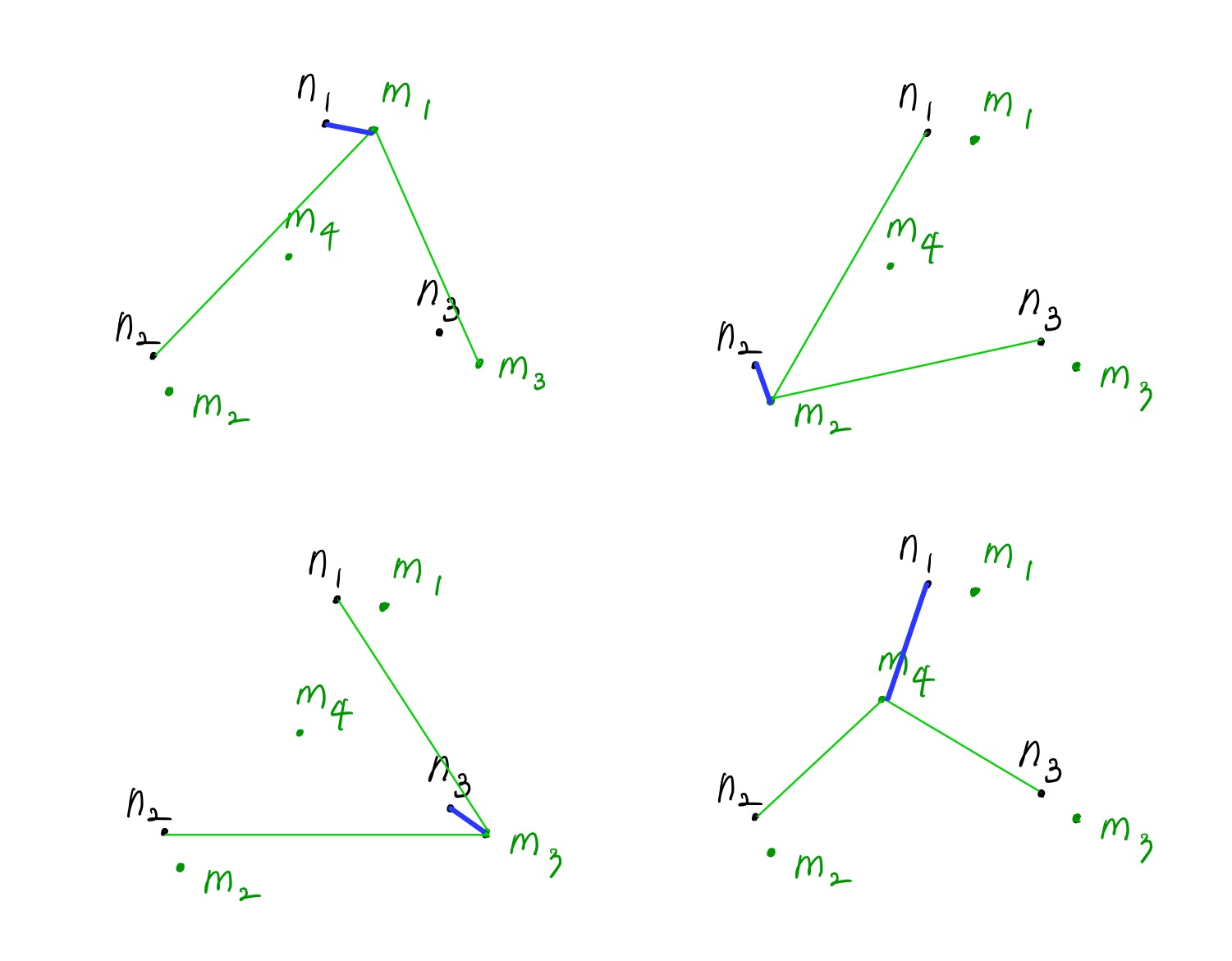
극단적인 예로, 아래와 같이 현재까지 sampling한 $\mathcal{M}_C= { n_1, n_2, n_3 }$이고, $m_1, m_2, m_3, m_4$ 중에서 다음 feature를 sampling 한다고 가정해 보겠습니다. 먼저 $m_1, m_2, m_3, m_4$ 각각을 기준으로 $n_1, n_2, n_3$과의 거리를 구한 뒤 최솟값을 찾습니다. 파란색으로 표시한 각각의 최소 거리 중 최댓값을 갖는 것은 $m_4$이므로, $m_4$를 sampling 합니다. $m_1, m_2, m_3$ 보다 $m_4$를 sampling 했을 때 Memory Bank 내 feature들이 고르게 분포함을 확인할 수 있습니다.
3. Anomaly Detection with PatchCore
마지막 단계는 이전 단계에서 구한 Memory Bank $\mathcal{M}$을 사용하여 image-level anomaly score $s$를 구하는 것입니다.
Step 1테스트 이미지 $x^{test}$의 patch feature들 $m^{test} \in \mathcal{P}(x^{test})$과Memory Bank$\mathcal{M}$에 속한 정상 patch feature들 $m \in \mathcal{M}$ 사이의 거리를 모두 구합니다.Step 2$m^{test}$별 거리 최솟값을 찾습니다.Step 3Step 2를 최대화하는 $m^{test}$와 $m$을 찾습니다. ($m^{test, \ast}, m^\ast$)Step 4Step 3에서 구한 $m^{test, \ast}, m^\ast$을 통해 maximum distance score $s^*$을 구합니다.
Step 5최종 image-level anomaly score $s$를 구하기 위해 $s^\ast$을 scaling 합니다. scaling $w$가 의미하는 것은, anomaly score가 작아지려면($w$가 작아지려면) $m^\ast$뿐만 아니라, $m^\ast$ 근처에 위치한 $b$개의 정상 patch feature들과의 거리도 가까워야 한다는 것입니다.
모델 성능 평가
Datasets
- MVTec
- 15개의 클래스
- 총 5354개의 이미지 (이 중 1725개는 테스트 이미지)
- 학습 데이터셋에는 정상 이미지만 담겨있고, 테스트 데이터셋에는 정상과 비정상 이미지가 모두 담겨있음
- 각각의 이미지는 $256 \times 256$ 사이즈로 resize한 다음 $224 \times 224$ 사이즈로 center crop하여 사용
- data augmentation은 사용하지 않음
- Magnetic Tile Defects (MTD)
- 총 1317개의 이미지 (정상 925개, 비정상 392개)
- illumination level과 이미지 사이즈가 다양함
- 정상 이미지의 20%인 185개의 이미지를 테스트 이미지로 사용
- Mini Shanghai Tech Campus (mSTC)
- MVTec과 MTD와 달리 산업 이미지가 아닌 보행자 영상 데이터셋
- STC 데이터셋 중 일부를 샘플링한 버전임
- $256 \times 256$ 사이즈로 resize하여 사용
Evaluation Metrics
- anomaly detection 성능 -
AUROC- AUROC는 ROC 곡선 아래의 면적을 의미합니다. ROC 곡선은 binary classification에서 비정상 클래스에 속하는 샘플을 비정상으로 정확히 예측하는 민감도(재현율, True Positive Rate)와 정상 클래스에 속하는 샘플을 비정상으로 잘못 예측하는 비율(1-특이도, False Positive Rate) 사이의 관계를 그래프로 나타낸 것입니다.
- ROC 곡선은 다음과 같이 구성됩니다.
- x축은 False Positive Rate(FPR)을 나타내며, FPR은 실제로는 정상인 샘플 중 비정상으로 잘못 분류된 샘플의 비율입니다. FPR = FP / (FP + TN)
- y축은 True Positive Rate(TPR)을 나타내며, TPR은 실제로 비정상인 샘플 중 정확히 비정상으로 분류된 샘플의 비율입니다. TPR = TP / (TP + FN)
- AUROC 값은 0과 1 사이의 값을 가지며, 값이 1에 가까울수록 분류기의 성능이 좋음을 의미합니다. AUROC 값이 0.5인 경우는 무작위로 분류하는 것과 동일한 성능을 나타내며, 1에 가까울수록 모델이 비정상과 정상 클래스를 잘 구분한다는 것을 의미합니다. 반대로, AUROC 값이 0에 가까우면 모델이 완전히 반대로 분류하고 있다는 의미입니다.
- AUROC 지표는 모델의 분류 임계값을 다양하게 변화시키면서 모델의 성능을 평가할 수 있으며, 불균형한 데이터셋에서의 성능 평가나 다양한 분류 임계값에서의 성능을 종합적으로 평가하는 데 유용합니다.
- anomaly segmentation 성능 -
pixel-wise AUROC,PRO- PRO 지표(Per-Region Overlap)는 주로 이미지 내의 비정상 영역이나 객체를 탐지하고 분할하는 작업에서 사용되는 성능 평가 지표 중 하나입니다. 이 지표는 예측된 비정상 영역과 실제 비정상 영역 사이의 overlap을 측정하여, 모델이 얼마나 정확하게 비정상을 탐지하고 위치를 예측하는지를 평가합니다.
- PRO 지표는 다음과 같은 방식으로 계산됩니다.
- 먼저, 이미지 내의 모든 실제 비정상 영역(ground truth regions)을 식별합니다.
- 각 실제 비정상 영역에 대해, 모델이 예측한 비정상 영역(predicted anomaly regions)과의 최대 overlap을 찾습니다. overlap은 일반적으로 IoU(Intersection over Union) 같은 메트릭을 사용하여 계산됩니다.
- 각 실제 비정상 영역에 대해 계산된 최대 overlap들의 평균을 취하여 PRO 값을 도출합니다.
- PRO 지표의 핵심 목적은 모델이 비정상 영역을 얼마나 정밀하게 분할하는지를 평가하는 것입니다. 이 지표는 단순히 비정상 영역의 존재 여부만을 판단하는 것이 아니라, 모델이 실제 비정상 영역의 형태와 위치를 얼마나 잘 포착하는지를 종합적으로 평가합니다. 따라서, PRO 지표는 특히 의료 영상 분석, 산업 공정에서의 결함 탐지 등 정밀한 위치 정보와 형태 정보가 중요한 분야에서 유용하게 사용됩니다.
- PRO 지표는 세밀한 영역 기반의 평가를 제공하기 때문에, 모델의 성능을 보다 구체적으로 이해하는 데 도움을 줍니다. 높은 PRO 값은 모델이 실제 비정상 영역을 정확하게 인식하고 분할하는 능력이 우수함을 의미합니다.
Anomaly Detection on MVTec AD
 PatchCore 실험 결과: image level anomaly detection
PatchCore 실험 결과: image level anomaly detection
 PatchCore 실험 결과: anomaly segmentation(AUROC)
PatchCore 실험 결과: anomaly segmentation(AUROC)
 PatchCore 실험 결과: anomaly segmentation(PRO)
PatchCore 실험 결과: anomaly segmentation(PRO)
- anomaly detection과 anomaly segmentation task 모두에서 다른 모델들보다 (어떤 memory bank subsampling 비율이든) PatchCore 모델의 성능이 높았습니다.
Inference Time
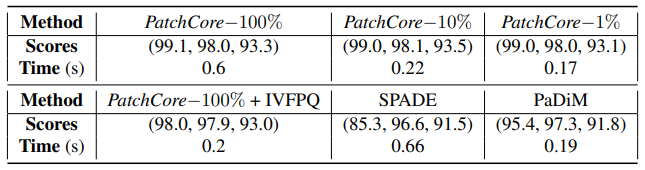
- coreset subsampling을 수행하지 않으면(PatchCore-100%) SPADE보다 성능은 높지만 inference time이 더 오래 소요됩니다.
- PatchCore-10%는 PaDiM보다 성능은 높지만 inference time이 더 오래 소요됩니다.
- coreset subsampling을 수행하지 않고, IVFPQ를 수행하면 성능이 떨어지고, (특히 image-level anomaly detection 성능이 하락) inference time도 PatchCore-1%보다 더 오래 소요됩니다. 하지만 그럼에도 여전히 SPADE, PaDiM보다는 성능이 높다는 것을 확인할 수 있습니다. coreset과 approximate nearest neighbour(ANN) 방법을 조합하면 dataset이 큰 경우에 inference time을 줄이면서도 어느 정도 성능을 유지할 수 있는데요. 본 논문의 저자들은 Faiss 라이브러리에서 제공하는 IVF 기반 ANN 기법을 사용했습니다. Faiss는 Facebook AI Research에서 개발한 오픈 소스 라이브러리입니다.